Phi-2:小模型的大能力
来源:互联网 更新时间:2026-05-30 14:46
最近,微软在小型语言模型(SLM)领域的动作频频,其Phi系列模型凭借“以小博大”的惊艳表现,给业界留下了深刻印象。特别是Phi-2,仅用27亿参数就在多个基准测试中超越了比自己大数十倍的模型,这背后到底藏着什么门道?今天就来拆解一下这个系列,尤其是Phi-2的核心技术细节。
Phi模型系列概览
先简单回顾一下Phi系列的发展脉络,它堪称是“教科书级”数据驱动的典范。
- :系列的开山之作,拥有13亿参数,专攻Python编程。在当时的SLMs中,它在编程基准测试中取得了顶尖的性能,证明了高质量数据在小模型上的巨大潜力。
Phi-1
- :同样13亿参数,但能力拓展到了常识推理和语言理解。它的表现足以和比它大5倍的模型相提并论,让业界看到了“小模型”的爆发力。
Phi-1.5
- :这才是真正的主角。27亿参数,却在复杂推理和语言理解上表现出色,一举成为130亿参数以下基础语言模型中的佼佼者。在编程和数学这类需要多步推理的任务上,它的表现甚至能媲美比它大25倍的Llama-2-70B模型。
Phi-2
Phi-2的核心洞察:数据为王,知识传承
Phi-2的成功,并非简单的参数堆砌,而是两个关键策略的胜利。
- 。传统观念里,模型参数越大,能力越强。但Phi-2打破了这一迷信。它的训练数据被严格筛选为“教科书级高质量”,并大量使用了合成数据集。这种做法让模型在常识推理和通用知识理解上,仅凭“好数据”就吃得很透。你可以把它想象成一个学生,用经典的教材而非杂乱无章的网络碎片去学习,效率自然更高。
训练数据质量:真正的胜负手
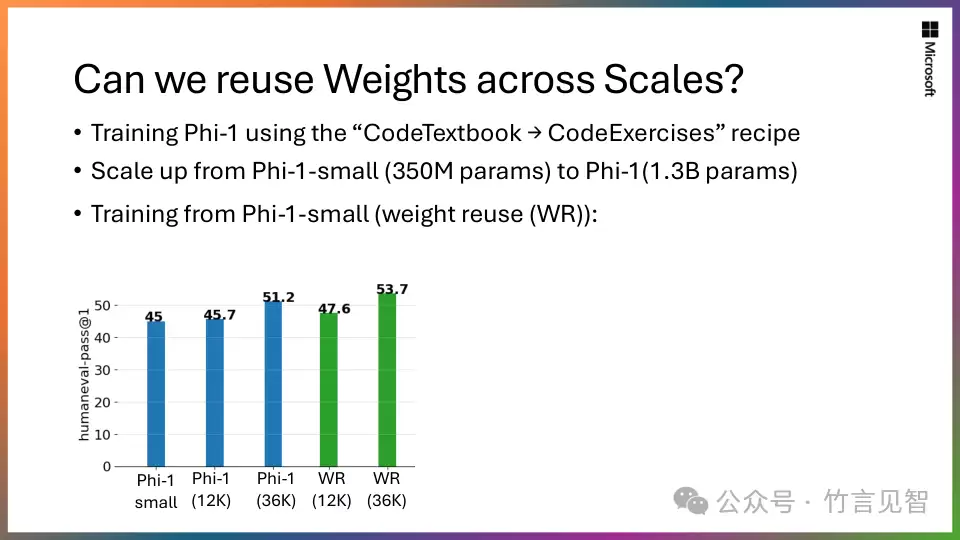
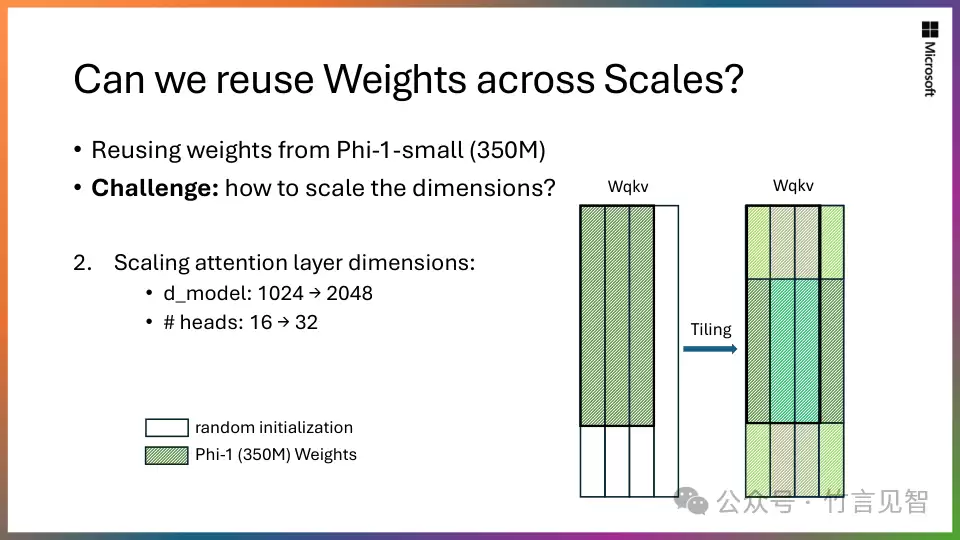
- 。从一个13亿参数的“小老师”(Phi-1.5)开始,将它的知识有效地“蒸馏”并嵌入到27亿参数的“大学生”(Phi-2)身上。这种规模化的知识转移策略,不仅大大加速了训练过程的收敛,更显著地拔高了Phi-2的最终性能基准。这不是简单的模型复制,而是一种智慧的“知识传承”。
可伸缩的知识转移:站在巨人的肩膀上
训练细节:14天,96块A100
这组数字很能说明问题:Phi-2使用了基于Transformer的架构,在1.4万亿(1.4T)个token上进行了训练。这些token全部来自上述的“教科书质量”数据以及合成数据集。
整个训练过程在96块A100 GPU上耗时14天。值得注意的是,Phi-2是一个纯粹的基础模型,它没有经过RLHF(人类反馈强化学习)的对齐,也没有进行指令微调。这意味它展现出的强大推理能力,完全是其预训练过程和高质量数据处理的结果。
评估表现:以小博大,甚至超越
这才是Phi-2最让人兴奋的地方。在BBH、常识推理、语言理解、数学和编程等一系列学术基准测试中,Phi-2的性能不仅全面超越了同量级的Mistral和Llama-2模型(这些模型参数在7B到13B之间),更是在多步推理任务上(编程和数学)超越了参数大它25倍的Llama-2-70B模型。此外,Phi-2的表现与谷歌当时发布的Gemini Nano 2模型也不相上下,甚至在某些方面更优,这无疑证明了在小模型赛道上,数据处理和训练策略的极致优化可以带来多大的优势。
安全性及偏见:意外的惊喜
通常情况下,模型越小,越容易出现不安全或带有偏见的输出。但Phi-2在这方面给出了一个惊喜。得益其定制的数据策划技术,它在安全性和偏见控制上的表现,甚至优于一些经过对齐的开源模型。这意味着,即使我们对它进行红队测试或评估,其行为也展现出令人放心的稳健性。


-
下饭影视APP下载安装指南
-
灵宝派对手游下载安装地址推荐
-
和平精英如何做到压枪稳-和平精英怎样才能压枪稳
-
下载浏览器app下载安装选择推荐
-
初中英语同步课文跟读APP推荐|免费下载高口碑跟读软件排行榜
-
BuuPo官网在哪下载 最新官方下载安装地址
-
4D采矿者官网在哪下载 最新官方下载安装地址
-
阅读app安卓版下载推荐
-
碎片人偶Vragmeet官网在哪下载 最新官方下载安装地址
-
Elysium Above 履云录官网在哪下载 最新官方下载安装地址
-
无尽花界时装合辑
-
免费影视剧APP推荐
-
喧哗番长乙女 2nd Rumble !!官网在哪下载 最新官方下载安装地址
-
纸嫁衣9官网在哪下载 最新官方下载安装地址
-
萌神契约手游下载安装
-
好用的手环阅读app下载安装
-
儿子穿新中式现身大会堂 马斯克罕见用中文回应:他正在学习普通话
-
人声接近真人!OpenAI一口气更新三款超强语音AI
-
名单曝光!库克、马斯克等将随团到访中国 黄仁勋不在其中
-
短视频软件推荐
-
2 企业AI只会报数、不敢决策?SmartBI白泽V5给出落地解法 05-30
-
3 海螺AI怎么让它模仿特定作者的文风来写文章? 05-30
-
4 从提示词工程到 Agent 工程 05-30
-
5 AI Coding 工具的未来:得物如何突破数仓开发的痛点 05-30
-
6 应用场景上“新” 推动人工智能与能源双向赋能 05-30
-
7 MiniMax,启动A股IPO 05-30
-
9 学习笔记:智能体中的工作流 05-30
-
10 Llama3.1-8B模型中文版!OpenBuddy发布新一代跨语言模型 05-30



