【每天学点AI】前向传播、损失函数、反向传播
来源:互联网 更新时间:2026-05-28 17:34
在深度学习的训练过程中,前向传播、反向传播和损失函数是最核心的三个环节。很多人刚接触时总觉得这三个概念很抽象,其实用一个简单的类比就能把它们的关系说清楚——就像教小朋友认数字一样。
前向传播:神经网络的“思考”过程
前向传播是神经网络计算的基础步骤:把输入数据逐层传递,经过权重和激活函数的加工,最终输出一个预测结果。整个过程可以拆解为“样本数据输入、算法模型、输出”三步。
举个生活化的例子:你给一个小宝宝看一张图片,问他“这是啥?”他会在脑袋里“思考”一下,然后告诉你答案。前向传播就是这个思考过程,只不过小宝宝换成了神经网络。
- :把图像、文字、语音等原始数据转换成电脑能识别的数字。就像小宝宝看到图片,神经网络也接收到一串数字。
样本数据输入
- :简单说就是一堆数学运算,核心是
算法模型
。线性层负责拟合线性关系,规则化层让计算更规整,激活层引入非线性——因为现实世界是非线性的。整个流程就是用这些公式去逼近非线性样本数据。线性层+规则化层+激活层
- :同样是一些数学运算(比如Linear或Conv),把模型处理后的结果转换成最终的预测值。
输出层
这个过程可以用下面的公式来表示:

损失函数:告诉神经网络它错了多少
损失函数就是衡量预测结果和真实标签之间的差距。它的作用很简单:像一个裁判,给模型的预测打分——分数越低,说明预测越准,模型越好。损失函数的存在,是为了让反向传播有据可依。还是那个例子:如果小宝宝猜错了,你会告诉他“不对哦,这是数字8,不是3”。损失函数就是这句纠正的话,告诉神经网络“你的答案有点偏差”。
以下是几种常用的损失函数:
L1 Loss(MAE)
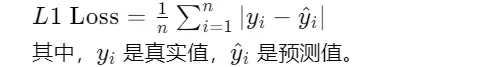
L2 Loss(MSE)
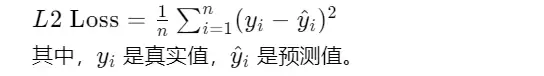
Smooth L1 Loss

反向传播:神经网络的“自我修正”过程
反向传播是利用损失函数的梯度来更新网络参数的过程。它从输出层开始,逆向通过网络,用链式法则计算每个参数对损失的敏感度。具体分三步:
- :先算出损失函数对输出层权重的敏感度。
计算输出层误差梯度
- :从输出层开始,一层层往回算,传递误差梯度。
逐层反向传播
- :用梯度下降算法,根据算出的梯度更新每层的参数。
更新权重和偏置
所以这三者的关系很清晰:
前向传播
损失函数
反向传播
掌握这三个概念,是理解更复杂机器学习算法的基础。无论你之后研究计算机视觉、自然语言处理还是其他方向,这个底层逻辑都会反复出现。特别提醒:2012年之后的深度学习模型,本质上都在用“线性+激活”来逼近复杂系统,这是通用的知识框架。
AI体系化学习路线

-
下饭影视APP下载安装指南
-
灵宝派对手游下载安装地址推荐
-
和平精英如何做到压枪稳-和平精英怎样才能压枪稳
-
下载浏览器app下载安装选择推荐
-
初中英语同步课文跟读APP推荐|免费下载高口碑跟读软件排行榜
-
BuuPo官网在哪下载 最新官方下载安装地址
-
4D采矿者官网在哪下载 最新官方下载安装地址
-
阅读app安卓版下载推荐
-
碎片人偶Vragmeet官网在哪下载 最新官方下载安装地址
-
Elysium Above 履云录官网在哪下载 最新官方下载安装地址
-
喧哗番长乙女 2nd Rumble !!官网在哪下载 最新官方下载安装地址
-
无尽花界时装合辑
-
纸嫁衣9官网在哪下载 最新官方下载安装地址
-
萌神契约手游下载安装
-
好用的手环阅读app下载安装
-
免费影视剧APP推荐
-
儿子穿新中式现身大会堂 马斯克罕见用中文回应:他正在学习普通话
-
人声接近真人!OpenAI一口气更新三款超强语音AI
-
名单曝光!库克、马斯克等将随团到访中国 黄仁勋不在其中
-
短视频软件推荐
-
1 Palantir启示录:交互革命带来哪些新机会 05-28
-
2 如何让灵珠AI根据工作记录快速生成周报 05-28
-
3 深演智能在港交所主板挂牌上市 05-28
-
5 可灵AI全球首发视频模型定制功能,助力AI视频创作 05-28
-
9 GPT-5.1 发布:更智能也更“人性化“的 AI 助手 05-28
-
10 漫威传奇以数字再续!“漫威之父”斯坦·李获AI复活,原汁原味声音重现 05-28



