AI数据中心的布线考量
来源:互联网 更新时间:2026-05-28 16:29
人工智能……几十年来一直是科幻小说不变的主题。荧幕上的反派角色,从 HAL 9000、终结者到《黑客帝国》里的机器人,几乎都在跟人类对着干,逼得我们必须想办法应对技术带来的威胁。不过,最近 DALLE-2 和 ChatGPT 的发布,让大众对 AI 的能耐产生了极大兴趣,也引发了一连串关于它怎么改变教育和工作的讨论。当然,AI 也是当下乃至未来数据中心增长的核心推动力。
什么是 AI?简单说,它包含三个层面:训练阶段,大量数据被喂进算法,算法从中“学习”;推理阶段,算法接触新数据,基于训练学到的内容生成新结论——比如判断一张照片是不是猫;还有生成式 AI,这就更有意思了,算法能根据简单提示“创作”出文本、图像、视频、代码等原始输出。
AI 计算靠的是图形处理单元(GPU),这种芯片专为并行处理而生,特别适合 AI。但训练和运行 AI 模型占用的算力惊人,单台机器根本扛不住。
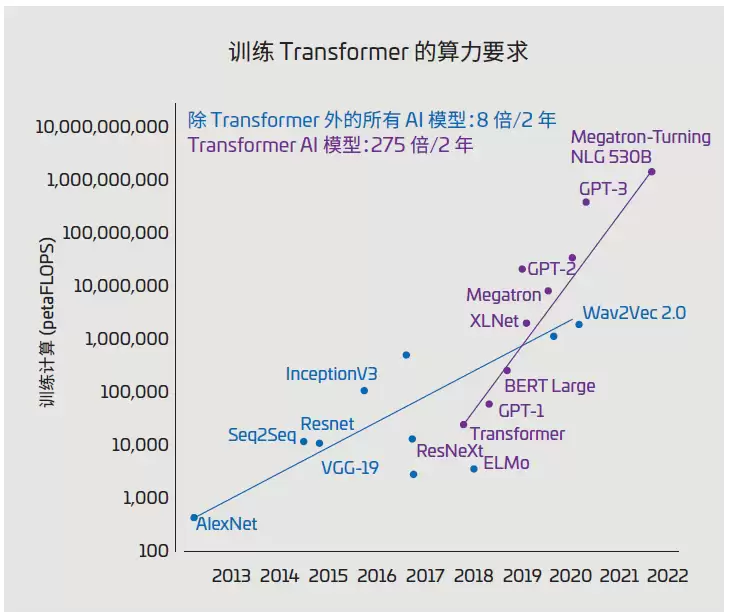
图 1:AI 模型大小(单位:petaFLOPS)
图 1 展示了 AI 模型规模的演进史,单位是 petaFLOPS(每秒千万亿次浮点运算)。处理这些大模型,需要多台服务器和机架上大量互联的 GPU。AI 数据中心通常会部署几十个这样的集群,而把这一切连起来、保证数据流动的布线基础设施,正面临一堆棘手的挑战。
下面就来聊聊 AI 数据中心布线的几个关键挑战与机遇,以及一些实用的最佳实践。
典型数据中心架构
几乎所有现代数据中心——尤其是超大规模的那种——都采用了折叠式 Clos 架构,也叫“分支和骨干”架构。在这里,所有分支交换机都连接到所有骨干交换机。具体来说,服务器机架连接到架顶交换机(ToR),然后 ToR 再通过光缆连到行末端的分支交换机,或者直接连到另一个房间。机架里的服务器,通常用一米到两米长的短铜缆连到 ToR,传输 25G 或 50G 信号。
这种配置能让数据中心用最少的光缆。比如 Meta 的 F16 架构(见图 2),每一行中的每个服务器机架只有 16 根双工光缆。这些光缆从 ToR 延伸到行末端,在那里与模块连接,把双工光纤组合成 24 根光缆,再延伸到另一个房间,连到分支交换机。
当数据中心引入 AI 时,会把 AI 集群部署在传统计算集群旁边。传统计算常被称为“前端网络”,AI 集群则是“后端网络”。
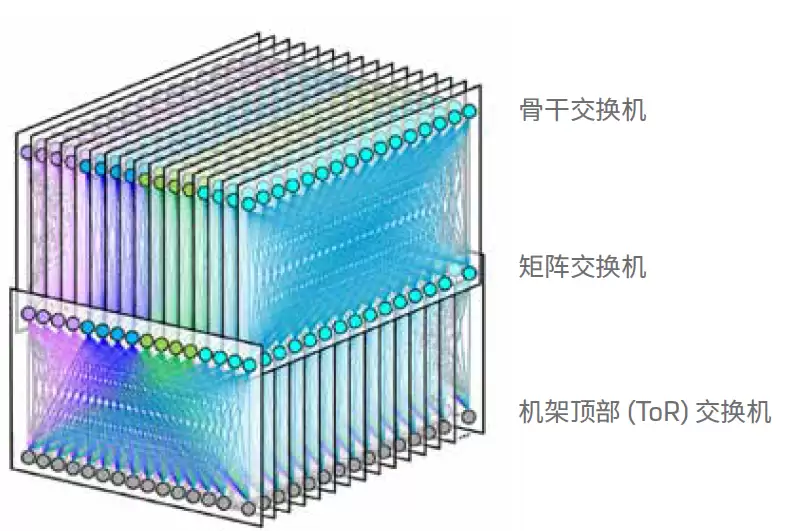
图 2:Facebook F16 数据中心网络拓扑结构
带有 AI 集群的数据中心
AI 集群有独特的数据处理需求,所以数据中心架构也得跟着变。GPU 服务器需要更多互联,但受限于功耗和散热,每个机架能放的服务器反而更少。结果就是,AI 数据中心里的机架间布线比传统数据中心多得多。每台 GPU 服务器都得连到行内或房间内的交换机,这些链路需要在远距离上跑 100G 到 400G 的速率,铜缆根本做不到。此外,每台服务器还得连到交换机网络、存储和带外管理。
举个例子:NVIDIA
看看 AI 领域扛把子 NVIDIA 的架构吧。他们推出的 DGX H100 GPU 服务器,有 4 个 800G 交换机端口(当作 8 个 400GE 来用)、4 个 400GE 存储端口,以及 1GE 和 10GE 管理端口。一个 DGX SuperPOD(图 3)能装 32 台这样的 GPU 服务器,这些服务器连到单行里的 18 台交换机。每行因此拥有 384 个 400GE 光纤链路用于交换网络和存储,还有 64 个铜缆链路用于管理。光纤链路数量大幅飙升。相比之下,前面提到的 F16 架构,在服务器机架数量不变的情况下,才有 128 根双工光缆(8x16)。
AI 集群的链路有多长?
在 NVIDIA 的理想场景里,AI 集群中所有 GPU 服务器都靠得很近。跟高性能计算(HPC)一样,AI/机器学习算法对延迟极其敏感。有人估计,训练大型模型有 30% 的时间耗在网络延迟上,70% 用在计算上。考虑到训练一个大模型成本可能高达 1000 万美元,这网络延迟就是一笔巨款。哪怕只省下 50 纳秒或 10 米光纤的延迟,效果也十分显著。所以,AI 集群里几乎所有的链路都限制在 100 米以内。
但问题来了,不是所有数据中心都能在同行里部署 GPU 服务器机架。这些机架大约需要 40 千瓦才能供电,这比典型服务器机架的功耗高得多。那些按较低功率要求建起来的数据中心,得专门腾出空间来放 GPU 机架。
如何选择收发器?
运营商得仔细琢磨 AI 集群该用哪种光收发器和光缆,才能把成本和功耗降到最低。前面说了,AI 集群里最长的链路也就 100 米。距离短,光学设备的主要开销就集中在收发器上。采用并行光纤的收发器有个天然优势:不需要用光复用器和分解复用器来做波分复用(WDM),这直接降低了成本和功耗。收发器省下来的钱,完全能抵消多芯光纤比双工光缆多出来的那点成本。比如,用带八芯光纤的 400G-DR4 收发器,就比用双工光缆的 400G-FR4 收发器划算得多。
单模和多模光纤都能支持长达 100 米的链路。随着硅光子技术的发展,单模收发器的成本降了不少,越来越接近多模收发器。市场数据显示,对于 400G 及以上的高速收发器,单模的成本还是多模的两倍。虽然多模光纤本身比单模稍贵,但多芯光纤的成本主要取决于 MPO 连接器,所以两者之间的实际差异并不大。
另外,高速多模收发器的功耗比单模少那么一两瓦。一个 AI 集群大约有 768 个收发器(128 个内存链路 + 256 个交换机链路 x 2),用多模光纤就能省下约 1.5 千瓦的功率。跟每台 DGX H100 消耗的 10 千瓦相比,这似乎不起眼,但对 AI 集群来说,任何降低功耗的机会都弥足珍贵。
2022 年,IEEE 短距离光纤工作组完成了 IEEE 802.3db 标准,为新的超短距离(VR)多模收发器确立了规范。这个新标准专门针对 AI 集群这样的行内布线,最大覆盖范围 50 米。这些收发器有望进一步降低 AI 连接的成本和功耗。
收发器与 AOC
很多 AI、ML 和 HPC 集群会使用有源光缆(AOC)来连接 GPU 和交换机。AOC 是两端集成了光发射器和接收器的光缆,通常用于短距离,且大多搭配多模光纤和 VCSEL。高速(>40G)的 AOC 会使用跟连接光收发器一样的 OM3 或 OM4 光纤。AOC 里的收发器不一定跟设备兼容,不兼容就无法工作。AOC 插上设备就能用,但因为安装人员测试的是内置收发器,所以不需要清洁和检查光纤连接器的技能。
不过,AOC 的缺点也很明显:它们缺乏收发器那种灵活性。安装 AOC 很耗时,因为布线时就得连着收发器。带扇出功能的 AOC 装起来尤其费劲。而且,AOC 的故障率是同等收发器的两倍。一旦 AOC 坏了,得通过网络重新安装新的,这会占用宝贵的计算时间。最后,升级网络链路时,还得把出问题的 AOC 拆掉换新的。相比之下,光纤布线属于基础设施,可以跨越多代数据速率,始终稳定运行。
结论
仔细规划 AI 集群的布线,能帮你省下成本、功耗和安装时间。合理的光纤基础设施,能让企业真正从人工智能中获益。

-
下饭影视APP下载安装指南
-
灵宝派对手游下载安装地址推荐
-
和平精英如何做到压枪稳-和平精英怎样才能压枪稳
-
下载浏览器app下载安装选择推荐
-
初中英语同步课文跟读APP推荐|免费下载高口碑跟读软件排行榜
-
BuuPo官网在哪下载 最新官方下载安装地址
-
4D采矿者官网在哪下载 最新官方下载安装地址
-
阅读app安卓版下载推荐
-
碎片人偶Vragmeet官网在哪下载 最新官方下载安装地址
-
Elysium Above 履云录官网在哪下载 最新官方下载安装地址
-
喧哗番长乙女 2nd Rumble !!官网在哪下载 最新官方下载安装地址
-
无尽花界时装合辑
-
纸嫁衣9官网在哪下载 最新官方下载安装地址
-
萌神契约手游下载安装
-
好用的手环阅读app下载安装
-
免费影视剧APP推荐
-
儿子穿新中式现身大会堂 马斯克罕见用中文回应:他正在学习普通话
-
人声接近真人!OpenAI一口气更新三款超强语音AI
-
名单曝光!库克、马斯克等将随团到访中国 黄仁勋不在其中
-
短视频软件推荐
-
1 网络快餐还是精神断粮?AI生成文章已全面碾压人类创作 05-28
-
3 网络快餐还是精神断粮?AI生成文章已全面碾压人类创作 05-28
-
4 天津的AI写作助手,它真的能改变你的创作方式吗 05-28
-
5 AI写作助手测评,科技的笔尖如何改变我们的写作世界 05-28
-
6 如何利用AI轻松生成租赁合同?一份详细的租赁合同撰写指南! 05-28
-
7 Palantir启示录:交互革命带来哪些新机会 05-28
-
8 如何让灵珠AI根据工作记录快速生成周报 05-28
-
9 深演智能在港交所主板挂牌上市 05-28



