一文读懂,可重构芯片为何是AI的完美搭档
来源:互联网 更新时间:2026-05-27 20:52
在数字化浪潮席卷全球的今天,人工智能(AI)无疑是那颗最耀眼的明星。从早期的机器学习算法,到如今深度学习和Transformer模型的广泛应用,AI技术正以前所未有的速度迭代演进。这种演进带来的直接结果,就是AI应用场景的爆炸式增长——从对功耗极其敏感的智能摄像头、家用物联网设备,到数据中心里处理海量请求的云端服务器,AI的身影无处不在。
然而,场景的多样化也带来了截然不同的硬件需求。在边缘端,设备往往“斤斤计较”每一瓦的能耗,却要完成实时图像识别这类复杂任务。而在云端,面对TB级的数据洪流和复杂的自然语言处理,强大的算力又成为刚需。无论身处何处,AI芯片都是决定应用成败的“心脏”。但问题也随之而来:当AI算法本身正变得日益复杂和多变时,传统固定架构的芯片,是否还能跟得上节奏?
现代神经网络模型作为AI算法的核心,具有一系列复杂多样的特征,这些特征对芯片的设计和性能产生了深远的影响。
首先,神经网络的“骨架”——拓扑结构,正变得越来越复杂。早期的网络主要由卷积层和全连接层简单堆叠而成。但为了追求更高的性能,像ResNet的残差连接、Transformer的注意力机制等复杂结构不断涌现。残差连接解决了网络深度增加时的梯度消失难题,而注意力机制则通过动态生成的权重矩阵,让网络能更“聪明”地聚焦于关键信息。看看特斯拉在2023年AI Day上展示的网络结构吧,其节点类型和连接方式之复杂,旨在模拟人脑的神经连接,这对芯片如何高效调度计算资源和数据流提出了前所未有的挑战。
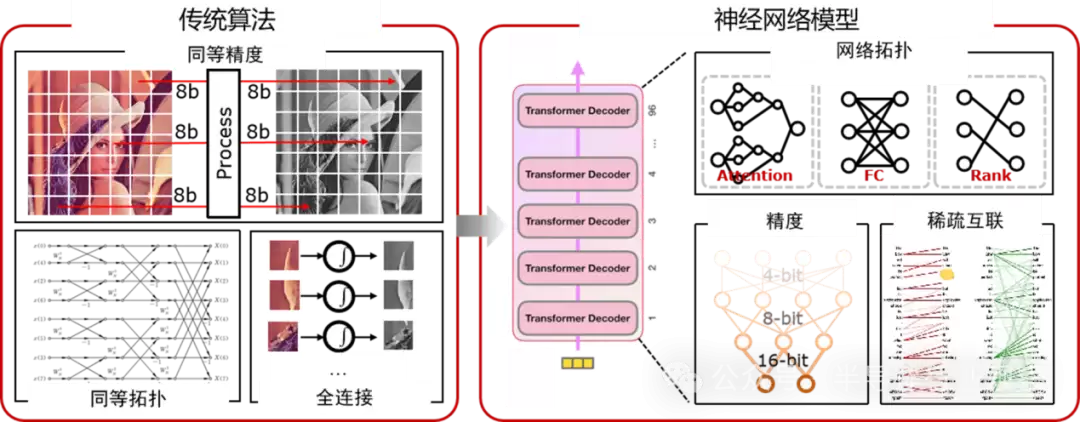 图1. AI算法呈现出复杂演变的特点
图1. AI算法呈现出复杂演变的特点
神经网络模型存在多维度的稀疏性,
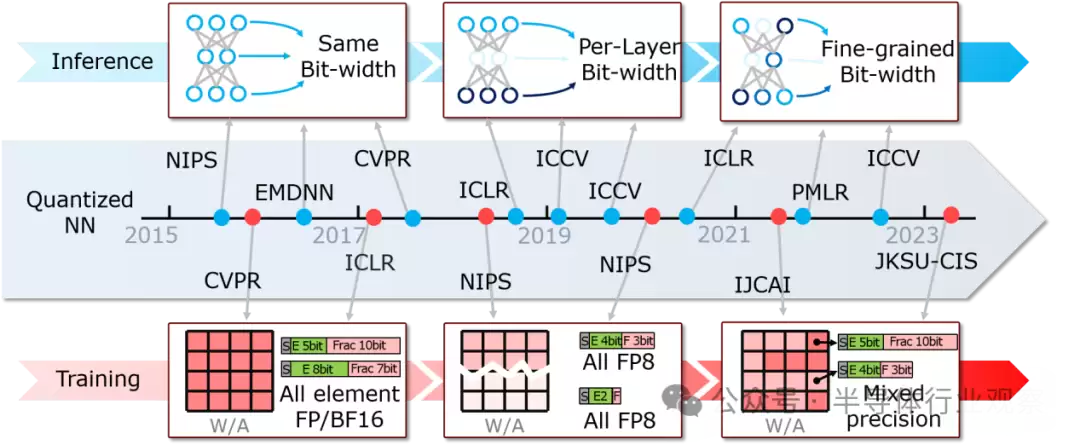
图2. 神经网络模型精度不断变化
此外,神经网络对数据精度的要求也呈现出高度的“弹性”。在推理阶段,从早期粗暴地将整个模型量化为统一的INT8精度,发展到为网络中每一层“量体裁衣”般设置不同精度,再到如今更极致的元素级混合精度,目标都是最大化计算资源的利用率。在训练阶段,为了在精度和能效间取得平衡,混合精度训练(如混合使用FP16和FP8)已成为主流方案,单纯使用高精度格式带来的内存和功耗开销已变得难以承受。
这些复杂的模型特征,给芯片设计师们抛出了一系列棘手难题。不同的网络结构导致数据重用模式千差万别,而访问内存(尤其是DRAM)的代价,在时间和功耗上往往远高于计算本身。因此,芯片必须具备灵活适配多种数据流的能力,以最小化数据搬运。同时,要充分利用稀疏性带来的红利,芯片需要能智能识别并跳过不同维度的零值计算。面对从INT4到FP16不等的多种精度要求,芯片内部的运算单元(如MAC)也必须足够“多才多艺”,能在不同精度模式间灵活切换,且不造成过多的面积和功耗开销。
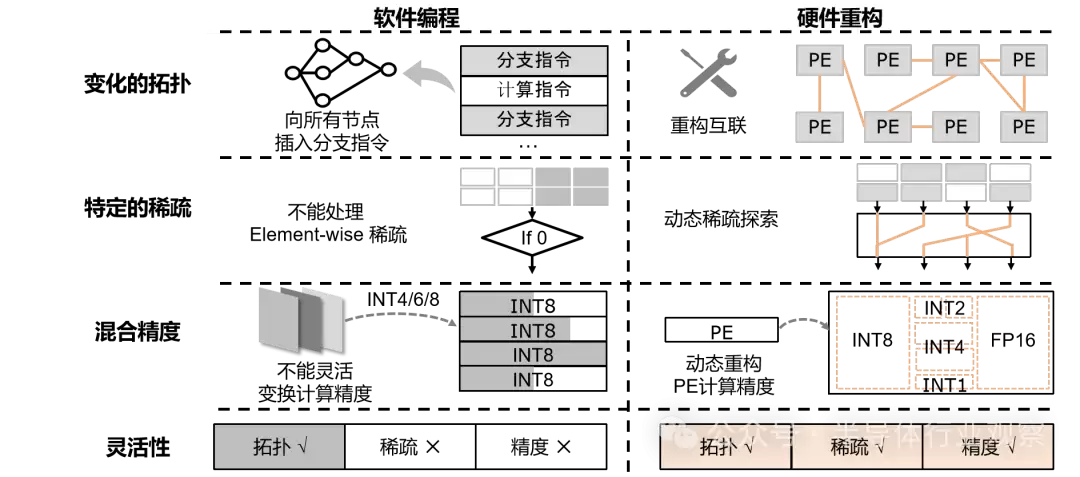
图3. 硬件重构优于软件编程
为应对这些挑战,硬件重构成为关键技术,
硬件重构主要在芯片级、处理单元阵列(PEA)级和处理单元(PE)级三个层次进行。
PEA 级重构
PE 级重构
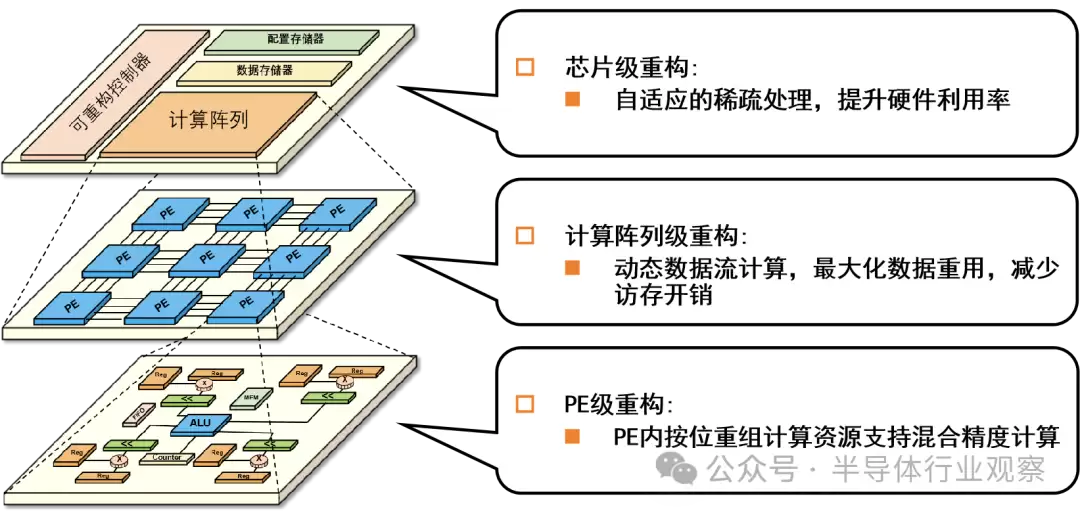
图4. 可重构芯片可实现多层次硬件重构
可重构芯片凭借芯片级、阵列级和 PE 级三级重构能力,在保持编程灵活性的情况下,通过对硬件资源的精细化重构调度和高效利用,实现更高性能和更高能效的 AI 芯片设计。
展望未来,随着AI算法持续演进和应用边界不断拓宽,可重构芯片的价值将愈发凸显。它有望成为支撑AI持续创新的坚实算力底座,推动整个产业迈向新的高度。从边缘到云端,这一技术路径正在被验证。无论是覆盖云边端场景的系列化芯片量产,还是源自顶尖学术机构的独角兽企业的涌现,都预示着可重构计算正从前沿探索走向大规模工程实践,其广阔的应用前景值得期待。
参考链接
1.Shouyi Yin. Reconfigurable Machine Learning Processor: Fundamental Concepts, Applications, and Future Trends.ASSCC 2023 Tutorial.

-
下饭影视APP下载安装指南
-
灵宝派对手游下载安装地址推荐
-
和平精英如何做到压枪稳-和平精英怎样才能压枪稳
-
下载浏览器app下载安装选择推荐
-
初中英语同步课文跟读APP推荐|免费下载高口碑跟读软件排行榜
-
4D采矿者官网在哪下载 最新官方下载安装地址
-
BuuPo官网在哪下载 最新官方下载安装地址
-
阅读app安卓版下载推荐
-
碎片人偶Vragmeet官网在哪下载 最新官方下载安装地址
-
Elysium Above 履云录官网在哪下载 最新官方下载安装地址
-
喧哗番长乙女 2nd Rumble !!官网在哪下载 最新官方下载安装地址
-
纸嫁衣9官网在哪下载 最新官方下载安装地址
-
萌神契约手游下载安装
-
好用的手环阅读app下载安装
-
无尽花界时装合辑
-
人声接近真人!OpenAI一口气更新三款超强语音AI
-
儿子穿新中式现身大会堂 马斯克罕见用中文回应:他正在学习普通话
-
名单曝光!库克、马斯克等将随团到访中国 黄仁勋不在其中
-
免费影视剧APP推荐
-
苹果macOS 27将优化界面设计并测试AI驱动的Safari标签页自动分组功能
-
1 2.8万台赋号,人形机器人“身份证”代表什么? 05-27
-
2 万卡集群网络选型:国产IB批量出货,改写行业性价比规则 05-27
-
4 天立国际控股罗实荣膺福布斯中国“人工智能影响力人物” 05-27
-
6 2026年 国内如何注册 Claude 账号教程 05-27
-
7 Claude 这个更新,让模型能力提升10%+! 05-27
-
8 从毛绒玩具到AI棋友,元萝卜引领六一选购向“智能进化” 05-27
-
9 人工智能热潮推高韩国芯片股,SK海力士市值突破1万亿美元 05-27
-
10 国科微AI ISP品牌 “圆鸮”震撼发布,推动图像处理技术跨越升级 05-27



