让大模型“边看边改”,视觉分割准确率直接上涨9% | ICML 2026
来源:互联网 更新时间:2026-05-27 20:17
视觉分割,听起来是个直白的任务:给模型一张图、一句话,让它把目标区域的像素圈出来。但实际操作起来,却常常“失手”。一旦目标含糊、被遮挡,或者需要结合常识推理才能定位,一次性猜出准确的掩码就变得相当困难。
问题的核心在哪里?复旦与创智联合团队的最新研究RSAgent给出了一个洞察:现有方法缺少的,或许不是更强的分割头,而是一个“确认和纠错”的过程。他们提出的框架,让多模态大模型通过多轮工具调用,像人类一样“边看边改”,最终生成更可靠的掩码。这项工作已入选ICML 2026。

实验结果显示,这一思路效果显著。RSAgent在需要复杂推理的ReasonSeg测试集上,gIoU指标相比Seg-Zero-7B提升了9.0个百分点;在RefCOCOg数据集上也取得了81.5%的平均cIoU。
开放语义分割,难在哪里
如今的多模态大语言模型(MLLM)已经能够流畅地描述图像、回答问题、理解物体关系。但真实的视觉系统需求不止于此。无论是交互式标注、机器人感知,还是设计编辑与工业质检,都要求模型能将语言理解精准地落实到像素区域。换句话说,
模型必须在“看懂语义”和“画准掩码”之间完成可靠的转换
真正的挑战在于“开放语义”。用户的指令往往不是简单的类别名,而是充满模糊性和推理需求的描述,比如“图中左侧正在被人拿起的物体”,或者“找出湍急水流中保障个人安全的装备”。前者考验空间关系理解,后者则需要场景常识和用途推理。面对这样的指令,模型如果只做一次前向预测,就很难验证自己是否选对了目标。
因此,现有技术路线的短板,或许并不在于“不能产生掩码”,而恰恰在于
“缺少一个确认与纠错的过程”
如何解决?让MLLM学会推理与行动
RSAgent的关键设计在于,
并非将MLLM直接改造成一个掩码解码器,而是让它成为一个能够调度视觉工具的智能体
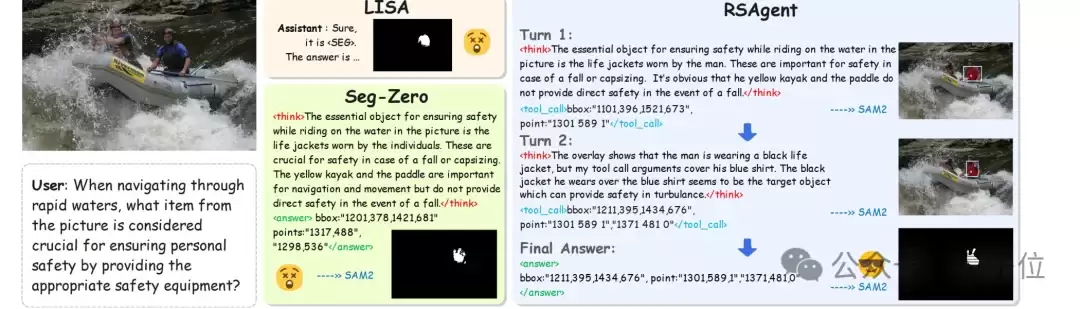
下图直观对比了LISA、Seg-Zero等单次预测方法与RSAgent多轮交互方式的区别。后者通过持续定位、观察和修正,逐步逼近目标。
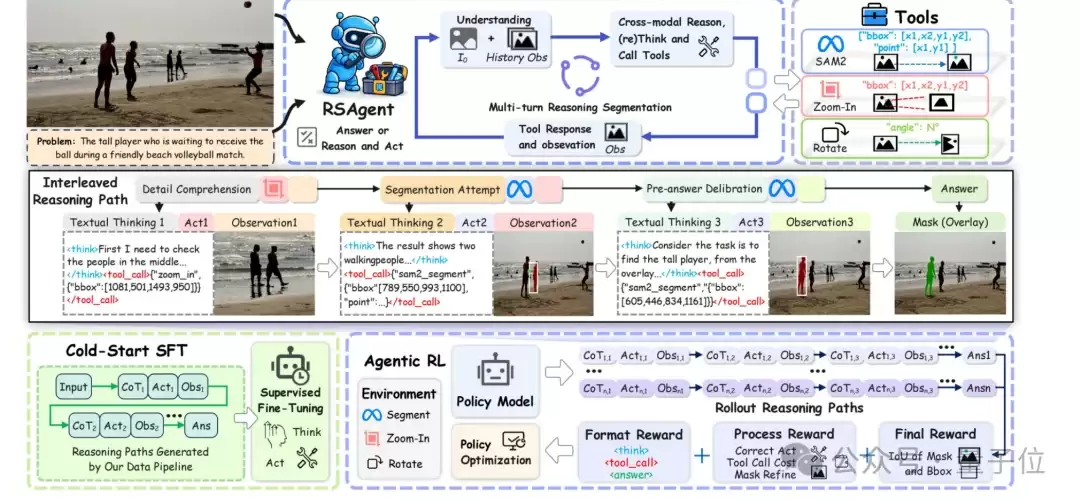
RSAgent的总体框架如下图所示,涵盖了多轮交互、工具调用、观察反馈,以及核心的训练策略:冷启动监督微调(cold-start SFT)和智能体强化学习(agentic RL)。
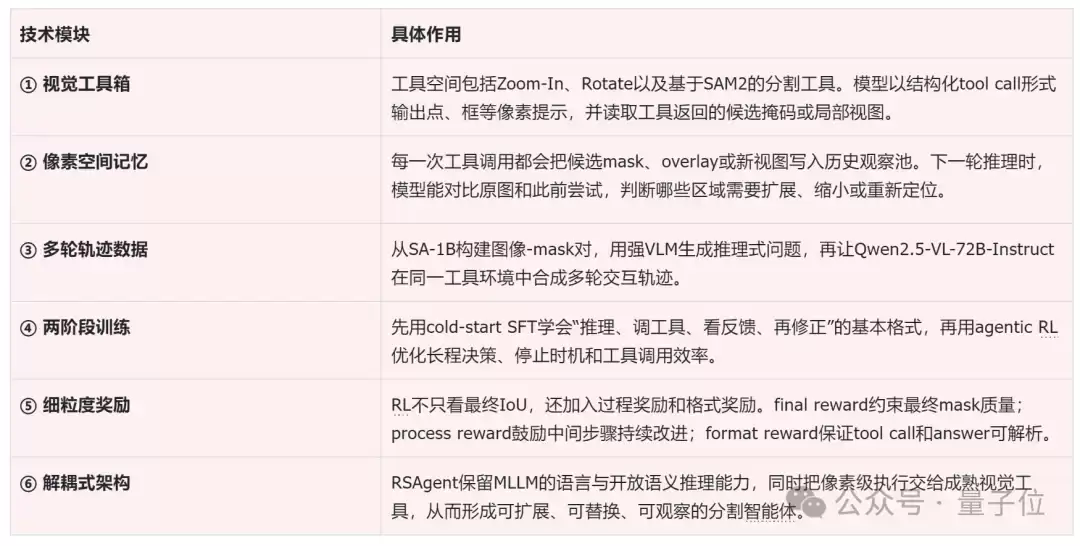
具体的技术模块及其作用,可以参考下图分解:
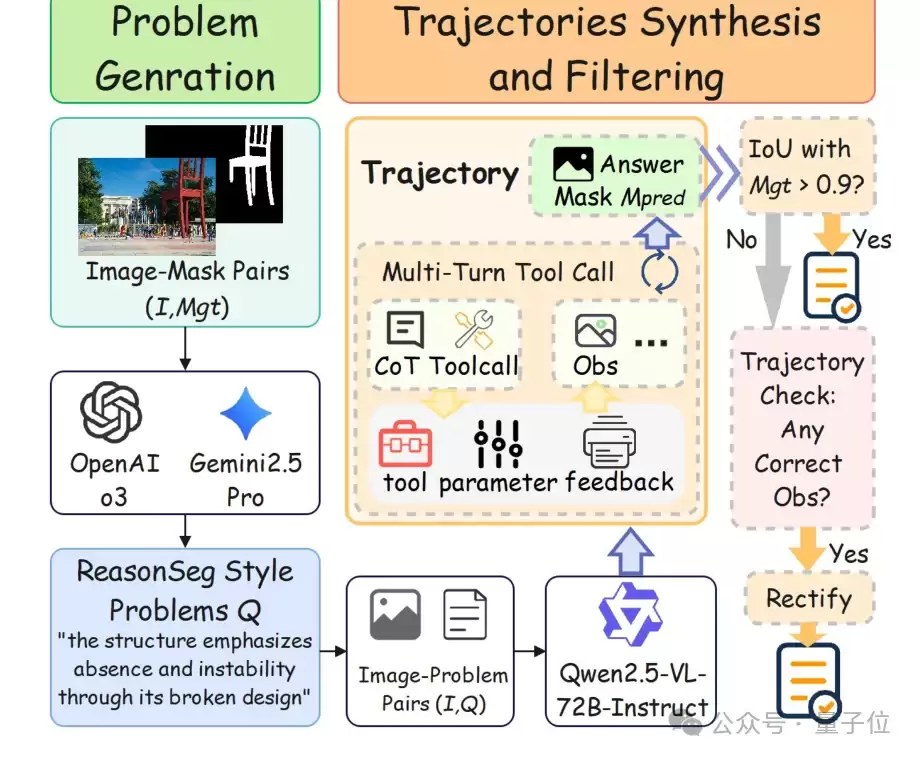
在数据构建层面,RSAgent通过自动合成与严格筛选来构建高质量的训练轨迹。论文中用于冷启动SFT的数据包含了约5千条高质量多轮推理轨迹;在RL阶段,则使用了约2千个强化学习示例,并额外加入了8千个RefCOCOg训练样本,让模型在交互环境中学习回报更高的工具调用路径。下图展示了其数据生成与过滤管线。
可以说,RSAgent的真正创新点不只是“调用了工具”,而是
将推理、工具、反馈与奖励闭环,整合为一个统一的训练体系
具体到一次交互,可以理解为四步循环:
- :读取图像与历史结果;
观察(Observation)
- :用自然语言分析当前候选区域是否满足指令;
思考(Thought)
- :选择工具并给出像素级提示(如点或框);
行动(Action)
- :接收工具输出并写入上下文,供下一轮参考。
反馈(Feedback)
这个循环让模型摆脱了对单次判断的依赖,拥有了逐步验证的机制。这对于处理关系型(如“左边的”)、属性型(如“红色的”)或需要隐含推理(如“能用来救生的”)的指令尤其有效。当目标很小、被遮挡,或需要根据动作和相对位置来判定时,RSAgent可以先进行粗定位,再查看局部区域,然后根据候选掩码的偏差重新指定提示点,从而多了一个可审查的中间过程。
在训练策略上,冷启动SFT解决了“会不会按格式工作”的问题,让模型掌握工具调用的语法和基本的反思流程;而智能体RL则解决了“怎样做得更好”的问题,通过奖励信号来优化多轮决策路径。两者结合,使得RSAgent既能稳定输出结构化结果,也能在复杂的开放语义样本上学习更优的决策。
实验结果:在ReasonSeg与RefCOCOg上取得领先
研究团队以Qwen2.5-VL-7B-Instruct为基础模型,SAM2-large作为分割工具,在RefCOCO系列和ReasonSeg基准上进行了系统评测。他们对比了传统视觉语言分割器、单次预测的MLLM分割方法、显式思维链/强化学习方法以及多轮工具调用智能体等多种方案。
下图表明,RSAgent在RefCOCO系列(RES)和ReasonSeg基准上均取得了领先的表现。
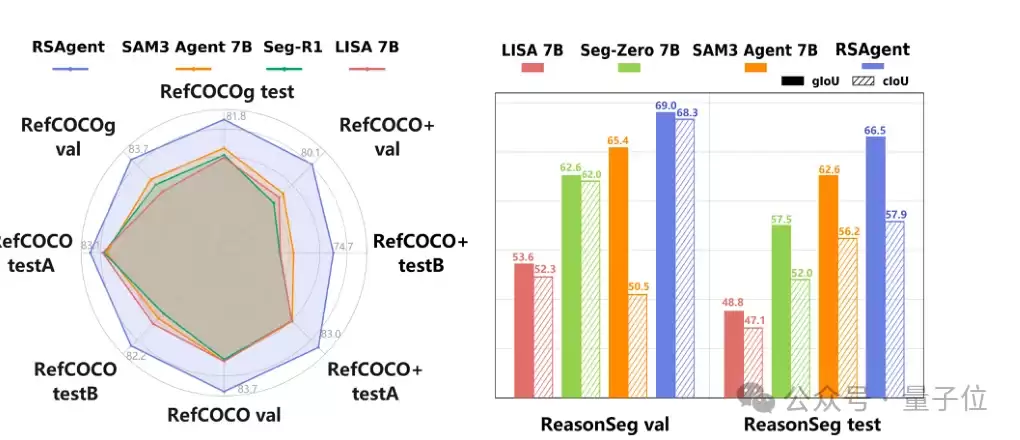
具体的评测数据如下:
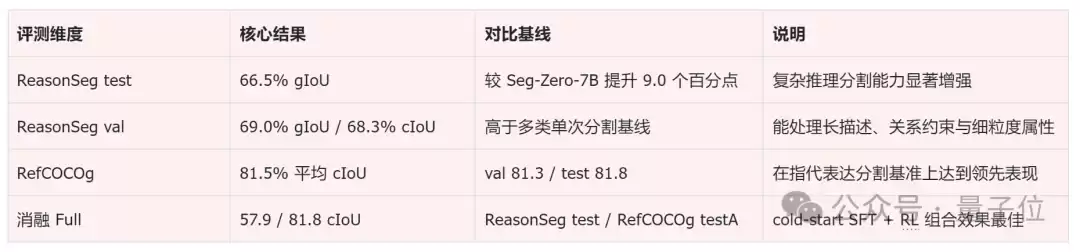
在ReasonSeg测试集上,RSAgent达到了66.5%的gIoU,相比Seg-Zero-7B的57.5%提升了9.0个百分点;在RefCOCOg上,平均cIoU达到约81.5%。这对于依赖开放语义推理的目标分割任务而言,意味着模型不仅能理解复杂描述,还能更稳健地将理解转化为准确的掩码。
消融实验进一步揭示,性能提升并非来自单一模块
先让模型学会规范的工具调用,再通过强化学习优化长程决策,是RSAgent成功的关键
下图展示了最大工具调用轮数的消融实验结果。适当增加交互轮数可以提升表现,但过长的上下文可能带来冗余和不稳定。
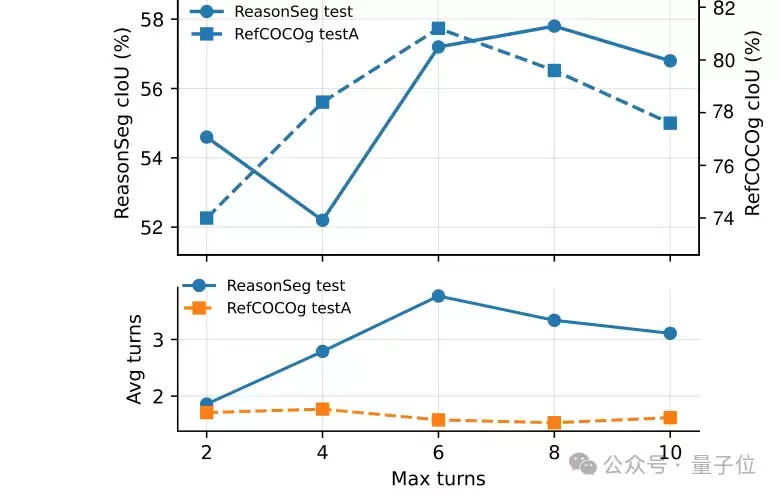
奖励函数的设计同样至关重要
迈向可验证的像素级行动空间
RSAgent的价值,远不止于刷新几个基准测试的指标。更重要的是,它展示了一条从“看图问答”迈向“视觉行动”的可行路径:
模型能够围绕文本目标,持续观察、调用工具、接受反馈、修正假设,并将最终判断精准地落实到图像像素上
这种能力对于构建交互式视觉系统具有普适意义:
- 在领域,它有望减少人工反复试错的成本;
数据标注
- 对于,它让模型能在执行操作前重新确认目标区域,提升安全性;
机器人感知
- 在中,它可以将自然语言意图转化为更稳定、可编辑的区域;
设计编辑与内容生产
- 面对,它则提供了一个可回看、可复核的中间过程,增强了结果的可信度。
科学图像分析
从更宏观的趋势来看,RSAgent成功地将开放语义理解、工具调用和像素级执行连接了起来。它证明,多模态大模型不必仅仅停留在“回答关于图像的问题”,而是可以进一步在视觉空间中主动探索、试错和自我修正。这个方向,将视觉智能体推进到了更接近真实任务需求的形态。
一言以蔽之,RSAgent证明了多模态大模型有能力从“结合文本与图像内容”的层面,进一步走向“在像素空间中推理、行动和自我修正”的新阶段。
这项研究由复旦大学、上海创智学院、上海交通大学等单位的团队合作完成。论文共同第一作者为何星旗与张钰杰。何星旗为复旦大学一年级硕士生,研究方向为视觉语言模型推理与强化学习;张钰杰为上海创智学院与复旦大学联合培养博士生,主要研究方向包括视觉语言模型推理、强化学习与大语言模型。
论文地址:https://arxiv.org/abs/2512.24023
项目代码:https://github.com/Nicola777-ai/RSAgent
-
下饭影视APP下载安装指南
-
灵宝派对手游下载安装地址推荐
-
和平精英如何做到压枪稳-和平精英怎样才能压枪稳
-
下载浏览器app下载安装选择推荐
-
初中英语同步课文跟读APP推荐|免费下载高口碑跟读软件排行榜
-
BuuPo官网在哪下载 最新官方下载安装地址
-
4D采矿者官网在哪下载 最新官方下载安装地址
-
阅读app安卓版下载推荐
-
碎片人偶Vragmeet官网在哪下载 最新官方下载安装地址
-
Elysium Above 履云录官网在哪下载 最新官方下载安装地址
-
喧哗番长乙女 2nd Rumble !!官网在哪下载 最新官方下载安装地址
-
无尽花界时装合辑
-
纸嫁衣9官网在哪下载 最新官方下载安装地址
-
萌神契约手游下载安装
-
好用的手环阅读app下载安装
-
免费影视剧APP推荐
-
儿子穿新中式现身大会堂 马斯克罕见用中文回应:他正在学习普通话
-
人声接近真人!OpenAI一口气更新三款超强语音AI
-
名单曝光!库克、马斯克等将随团到访中国 黄仁勋不在其中
-
短视频软件推荐
-
1 智谱唐杰:80年历史的计算机架构都要被AI颠覆 未来不再传统桌面 05-13
-
2 Qoder大模型智能写作实战:从大纲设计到全文润色的全自动化流程 05-26
-
3 大模型第一梯队来了新玩家,市场还没反应过来? 05-26
-
5 AI“治安官”上岗周年:抖音大模型治理谣言,处置浏览量下降62% 05-26
-
7 使用豆包大模型构建 AI 搜索引擎完整指南 05-27
-
8 最高降99%,小米大模型API永久降价 05-27
-
9 大模型选型:选择适配的智能体核心引擎 05-27
-
10 如何用豆包大模型实现 AI 面试官系统 05-27



