0.9B跑出90%真机成功率,上海交大为VLA补上空间感
来源:互联网 更新时间:2026-05-26 16:01
机器人看得见,但不一定看得准。这几乎是当前视觉-语言-动作(VLA)模型面临的一个普遍困境。大量模型仍然主要依赖二维视觉信息,一旦遇到需要精确定位、细微摆放或是判断物体遮挡关系的任务,成功率就会大打折扣。
要补上空间感知这块短板,通常有两条路可走,但各有各的代价。显式3D路线依赖深度传感器和点云重建,硬件链路长,对设备标定误差非常敏感;隐式3D路线则试图直接从RGB图像中学习几何信息,虽然省去了额外硬件,但不少方案依赖庞大的基础模型,训练和推理的成本都居高不下。
现在,上海交通大学MINT实验室团队提出了一条颇具巧思的中间路线:
Evo-Depth
0.9B

从结果来看,它在仿真基准测试中表现不俗:Meta-World任务上达到84.4%成功率,LIBERO任务上更是高达95.4%。部署到真实机器人上,平均成功率也能维持在90%左右。更关键的是部署开销:仅需约3.2 GB的GPU显存,推理频率能达到约12.3 Hz。
代码、模型权重及训练脚本均已全面开源。
轻量、可端到端训练
轻量、可端到端训练
Evo-Depth的核心设计思路非常清晰:从多视角的RGB图像中提取紧凑的隐式深度表征,再以轻量化的方式将其融入视觉-语言通路,最终通过一个基于flow-matching的动作专家模块输出连续、精细的动作指令。
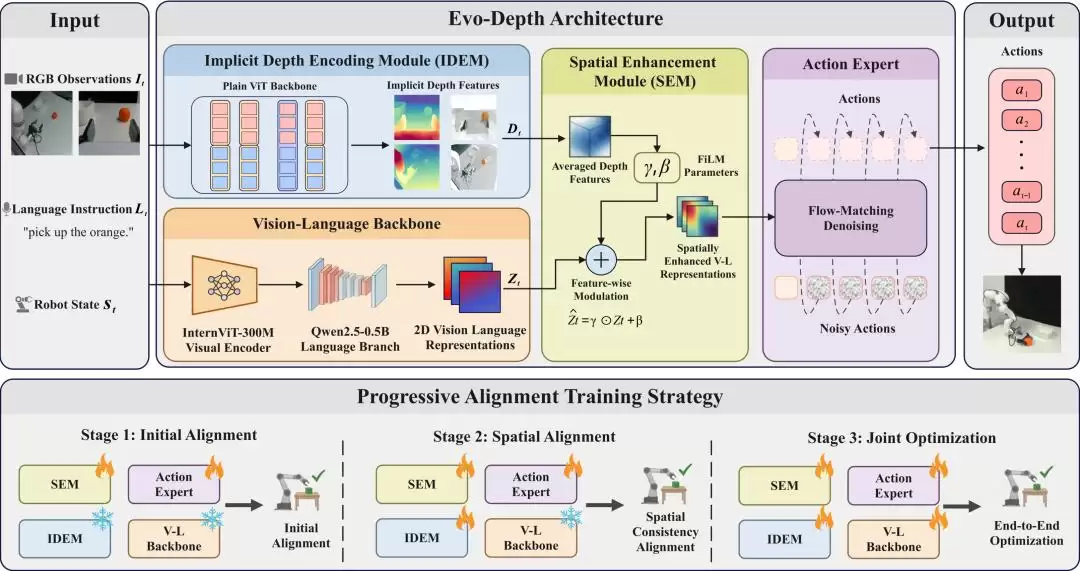
整个系统架构可以拆解为三个关键部分:
1. 隐式深度编码模块(IDEM)
这个模块的任务是从多视角图像中提取隐式深度特征。它的重点不在于生成高成本的、显式的3D中间表示(如点云),而是强调捕捉空间布局和相对几何关系。为了实现轻量化,IDEM的主干网络参数控制在约0.13B,并借助多视角深度预训练进行初始化,从而在参数有限的前提下,引入了与深度相关的先验知识。
2. 空间增强模块(SEM)
SEM的作用是将IDEM提取的隐式深度特征,作为一种调制信号,来增强视觉-语言联合表征。这种融合方式比直接增加一个独立的深度处理分支要克制得多:原有的视觉语言模型(VLM)继续专注于语义理解,而深度特征则主要负责提供空间信息的补充。这种分工协作的设计,旨在提升性能的同时,尽可能控制延迟和显存开销。
3. 渐进式对齐训练
当多个模块需要联合训练时,优化过程很容易变得不稳定。为此,研究团队采用了渐进式对齐训练策略。训练分阶段进行:首先对齐深度表征,然后进行多模态融合,最后再学习动作策略。这种分步走的方法,有效提升了训练的稳定性和最终效果。动作头则采用了当前VLA领域较为流行的flow-matching方法。
在总参数约0.9B的配置下,论文报告的综合性能如下:
仿真基准:
真机测试:
部署指标:
值得注意的是,除了关注基准测试分数,论文也明确给出了部署侧的开销与实时性指标。对于最终需要运行在机器人实时控制回路中的VLA系统而言,这部分信息的重要性,丝毫不亚于任务成功率。
性能、成本与实时性的折中艺术
性能、成本与实时性的折中艺术
归根结底,Evo-Depth试图解决的是一个非常实际的问题:
如何在不显著增加系统整体负担的前提下,有效提升VLA模型的空间感知能力。
从结果看,它确实找到了一种平衡:相比纯二维的VLA模型,它补充了关键的空间信息;而相比那些更“重”的、依赖显式3D或庞大基础模型的方案,它又最大限度地保留了部署的效率和可行性。
对于正在深耕机器人操作、空间智能或VLA系统开发的团队而言,这类在
性能、成本和实时性
-
俄罗斯最大yandex入口外贸日报直达链接
-
Bubbly无法连接服务器修复方法
-
盖乐世社区怎么删除帖子?盖乐世社区个人发布内容撤回步骤
-
美好的简约网名男生(精选100个)
-
新浪人工智能热点小时报丨2026年06月20日02时_今日实时人工智能热点速递
-
问题:CIA币好不?Cia Protocol币今日上线:价格预测、代币经济学和未来潜力
-
国际贵金属走低,现货黄金价格跌0.49%
-
欧易OKX官方网站直达入口 2026欧易官方App安卓版v7.1.0下载安装
-
倒数日怎么注册 倒数日账号注册教程
-
币安Binance官方中文网站 币安App最新版下载及新手注册指南
-
动漫《KiraKira 光之美少女 A La Mode》剧情介绍
-
币安Binance交易所官方入口 币安App下载安装与实名注册教程
-
Siren (SIREN)币价格预测 2026-2050:SIREN 股价会很快达到 1.5 美元吗?
-
高质量网名伤感男生英文(精选100个)
-
淘宝直播如何看回放在哪里看?怎么查看淘宝直播回放
-
以太坊(ETH)未来数周或持续呈现低迷态势,多重因素制约价格走势
-
《梦幻西游》特殊鬼怪怎么抓-隐藏变异鬼应对要点
-
漫威新剧《钢铁侠和他的超能朋友们》今日炸更11集,Thor和Loki惊喜客串
-
动漫《欢迎来到实力至上主义教室》剧情介绍
-
七麦数据官网网页地址 七麦数据官方入口在线首页
-
1

- 网名带郑和霍字的网名女有哪些
- 角色扮演 | 1
-
1 EveryThing怎么筛选图片 11-03
-
2 蚂蚁集团董事长井贤栋及夫人向母校上海交大捐赠1.3亿 03-17
-
3 0.9B跑出90%真机成功率!上海交大为VLA补上空间感 05-26



