首次,纯人类视频预训练VLA灵巧操作,少量数据微调就能部署成功
来源:互联网 更新时间:2026-06-09 15:05
实现具备人类水平的灵巧操作能力——这大概是机器人学领域里,一个听起来令人振奋、做起来却无比骨感的“硬骨头”挑战。
多指灵巧手在硬件上确实越来越像样了,但想让它们像人一样干活,难在数据。高质量的机器人动辄需要耗费大量人力物力去采集,以至于在所有视觉-语言-动作(VLA)模型里,数据规模这块一直是短板,跟大语言模型(LLM)和视觉语言模型(VLM)的数据量级比起来,几乎不在一个量级上。这也直接限制了模型在真实复杂任务中的泛化能力。
微软亚洲研究院和清华大学联手,最近放出了一项有意思的研究——论文《Scalable Vision-Language-Action Model Pretraining for Robotic Manipulation with Real-Life Human Activity Videos》提出的
VITRA

这项研究的核心思路很明确:能不能搞一套全自动的流程,把网上那些海量、且毫无标注的真实人类活动视频,自动转化成机器人V-L-A模型能直接吃的数据?
团队做到了。他们通过提取视频中的3D手部运动轨迹,进行原子级动作分割,再自动生成语言指令,最终构建了一个包含100万个片段、2600万帧的
超大规模手部V-L-A数据集
有了这个“大食堂”,模型在纯人类视频上预训练完成后,进入完全没见过的真实环境,竟然展现出了相当不错的零样本(Zero-Shot)手部动作预测能力。再配合少量真实机器人数据进行微调,就能在真实机器人上实现
高成功率
下面展开聊聊。
打通从人类视频到机器人数据的转化链路
打通从人类视频到机器人数据的转化链路
最大的难题,显然是如何填平非结构化人类视频与结构化机器人数据之间的鸿沟。既要高质量的动作标签,又要精准的语言指令,这条路怎么走?
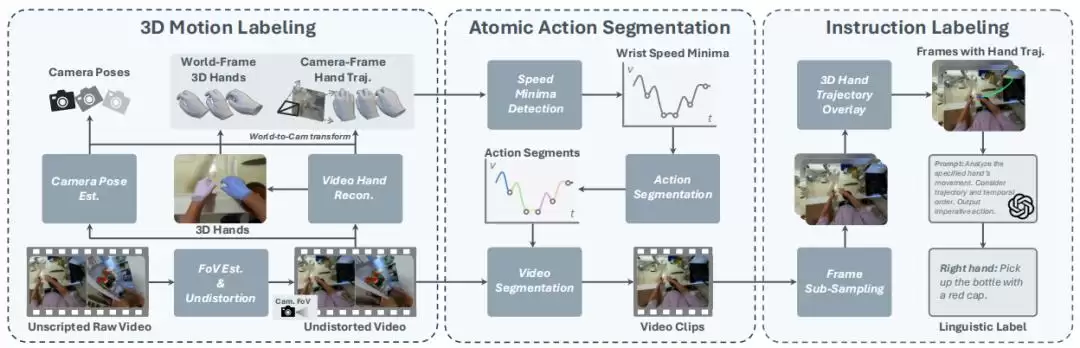
研究团队构建了一套包含三大核心技术的完整体系,实现了
从原始视频到V-L-A数据的无缝转化
△
3D运动标注:精准恢复手部与相机轨迹
3D运动标注:精准恢复手部与相机轨迹
首先,从单目、未标定且相机可能移动的视频中,要恢复出精确的3D手部运动,这本身就是个不小的挑战。
他们提出了一种
基于最新3D视觉技术的单目相机和手部姿态跟踪方法
原子级动作分割:基于速度极小值的自然切分
原子级动作分割:基于速度极小值的自然切分
现有机器人V-L-A数据大多是短视距的原子级任务,如何从长视频中精准切出这些片段?研究团队发现,人类动作有自然的节奏——在动作转换期间,手部速度通常会出现变化,而速度极小值往往就标志着切换点。于是,他们设计了一个简单却高效的分割算法:
基于3D空间中手部移动速度的极小值进行切分


指令标注:结合3D轨迹的精准动作描述
指令标注:结合3D轨迹的精准动作描述
给分割好的片段生成语言指令,团队巧妙地将视觉语言模型(VLM)和3D手部轨迹结合了起来。对于每个片段,系统均匀采样8帧图像,并把手掌的3D轨迹投影叠加到图像上,然后将这些带有轨迹高亮的图像输入给
GPT-4
实现强大的零样本预测与真实世界泛化
实现强大的零样本预测与真实世界泛化
基于自动构建的超大规模人类手部V-L-A数据集,团队设计并训练了一个
VLA模型
△
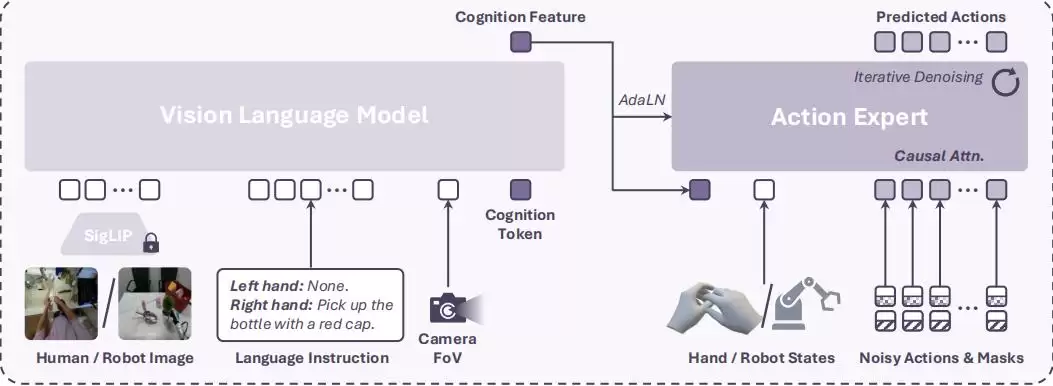
1、结合VLM与扩散动作专家的模型架构
1、结合VLM与扩散动作专家的模型架构
模型由VLM骨干网络(PaliGemma-2)和一个扩散动作专家(Diffusion Transformer,DiT)组成。VLM负责处理视觉观察、语言指令和相机视场角(FoV),输出“认知特征”(Cognition Feature)。而扩散动作专家则接收该认知特征、当前手部状态以及带有掩码的噪声动作块,通过迭代去噪预测未来的手部动作序列。值得注意的是,模型采用了因果注意力(Causal Attention)机制处理动作去噪,确保每个动作步骤的预测仅依赖于之前的动作,避免了零填充带来的干扰。
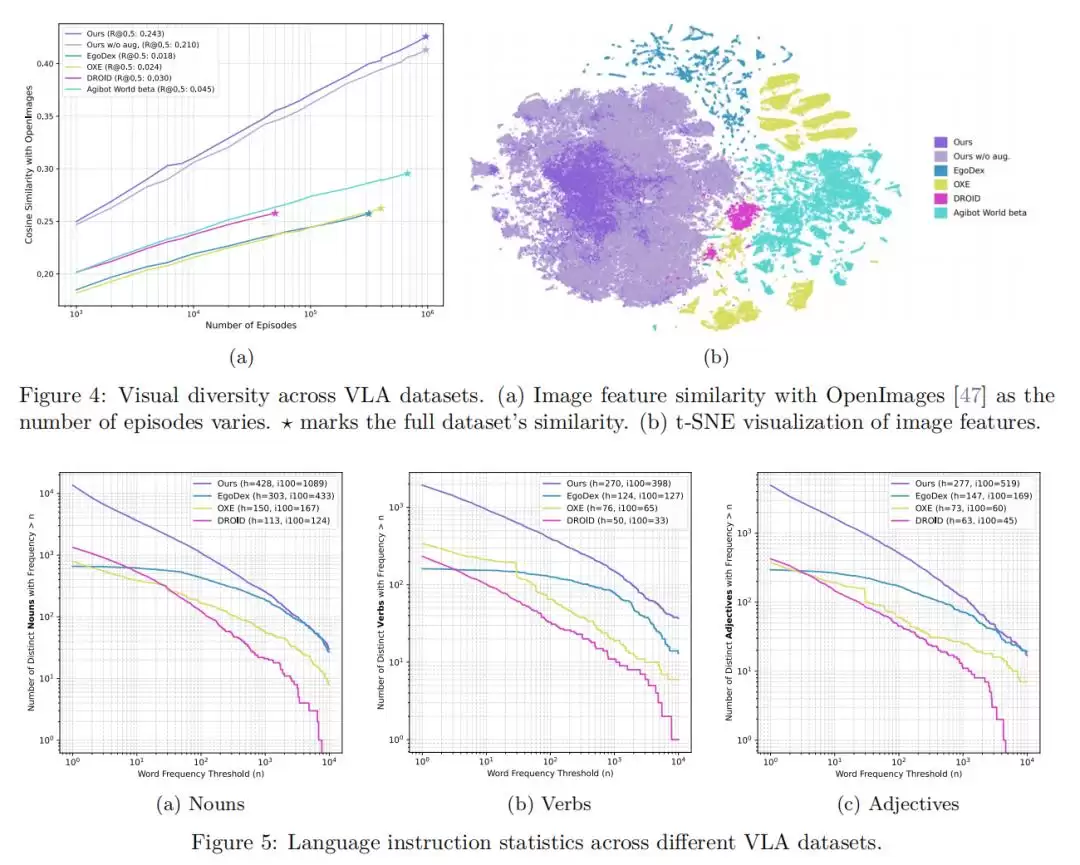
2、零样本手部动作预测:在未见环境中展现惊人能力
2、零样本手部动作预测:在未见环境中展现惊人能力
在完全未见的真实生活环境中,预训练模型展现出的
零样本手部动作预测能力
△
在抓取和一般动作预测的评估中,该模型显著优于仅在实验室环境下收集的数据(如EgoDex)上训练的模型,也优于使用原始人类标注数据训练的模型。这充分说明:用海量、多样化的真实生活视频进行预训练,确实能极大提升模型在复杂环境和未知物体上的泛化能力。
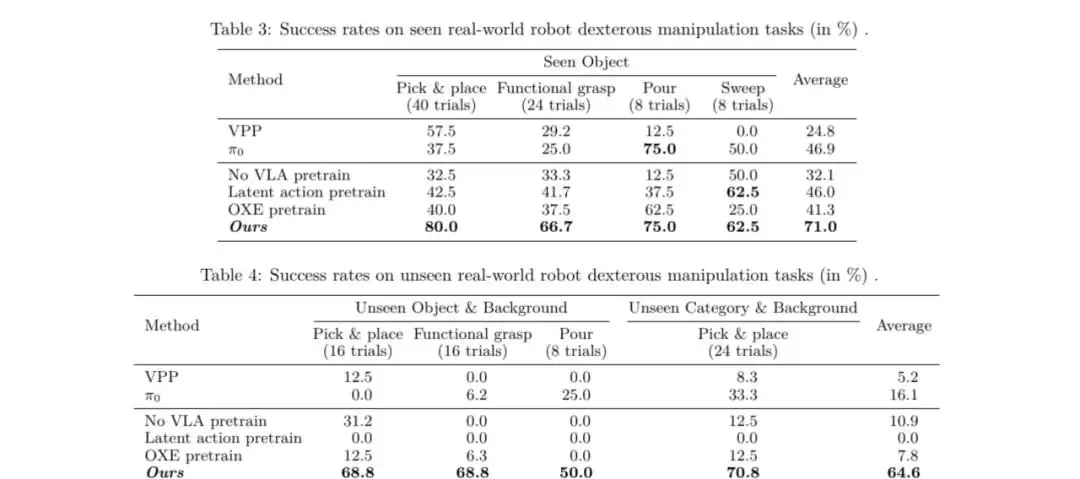
3、真实机器人灵巧操作:少量数据微调实现高效部署
3、真实机器人灵巧操作:少量数据微调实现高效部署
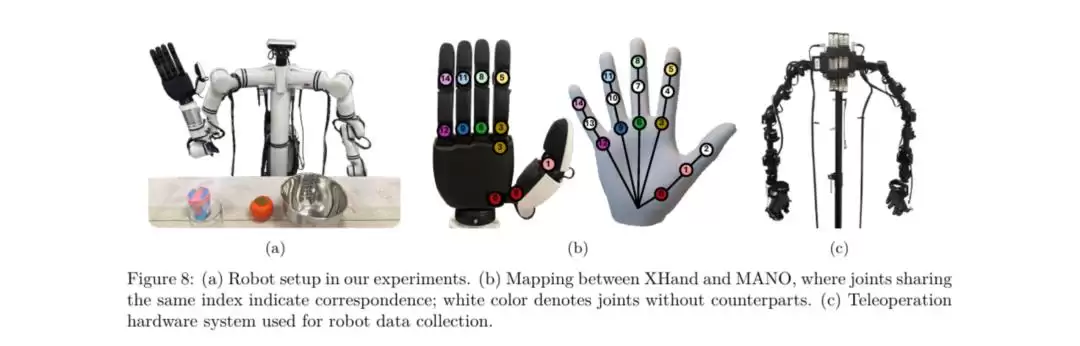
为了在真实机器人上部署,团队将人类手部的动作空间与机器人灵巧手(比如Realman机器人配备星动XHAND1)的动作空间进行了对齐。
△
只需要使用少量(约1.2K条)真实机器人遥操作数据对预训练模型进行
微调
任务成功率
鲁棒性
VITRA真实世界部署的硬件核心支撑
VITRA真实世界部署的硬件核心支撑
VITRA框架为何能在真实机器人上实现惊艳的泛化能力?算法革新固然重要,但底层硬件——星动纪元自研的国内首创全直驱五指灵巧手
星动XHAND1
△
高精度URDF与人类手部动作空间的无缝对接
高精度URDF与人类手部动作空间的无缝对接
VITRA框架的核心突破在于将人类手部动作空间与机器人灵巧手的动作空间进行
对齐

星动XHAND1官方提供的URDF模型精度很高,不仅精确描述了运动和动力学参数,还完美映射了人类手关节的空间分布。这种“数字孪生”级别的模型支持,让VITRA在微调阶段能够将人类关节角度精准映射到星动XHAND1的对应关节上,大幅降低了从人类视频到真实硬件的现实鸿沟,确保了预训练策略在真实硬件上的高效部署。
全直驱架构与高频响应:完美执行复杂灵巧操作
全直驱架构与高频响应:完美执行复杂灵巧操作
执行倾倒、清扫等复杂灵巧操作时,机器人需要极高的动态响应能力。星动XHAND1采用的全直驱(Direct-Drive)电机架构,为这一算法提供了最理想的硬件基础。全直驱设计从根本上消除了传统减速器带来的摩擦、迟滞和非线性干扰,赋予灵巧手超灵敏的动态响应能力,使其能够瞬间且精准地执行VITRA模型输出的动作指令,安全地操作各种未知物体。
丰富的传感器阵列:为未来多模态感知预留空间
丰富的传感器阵列:为未来多模态感知预留空间
虽然当前的VITRA模型主要依赖视觉输入,但星动XHAND1配备的丰富传感器阵列(如高分辨率触觉阵列)已经为未来的多模态感知预留了空间。结合星动XHAND1强大的硬件感知能力,未来的VLA模型有望进一步融合触觉反馈,处理更精细、更复杂的“指尖步态(Finger Gaits)”任务。
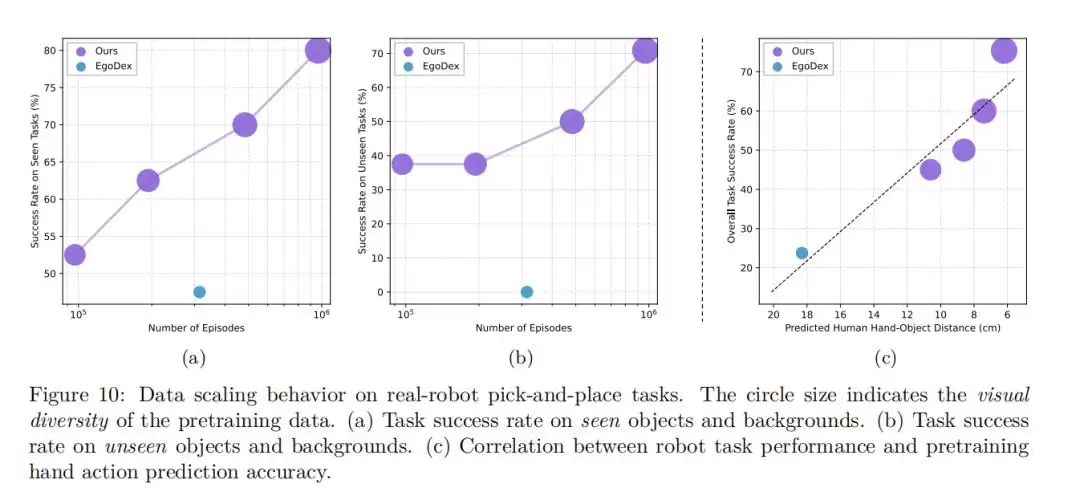
数据规模的缩放定律
数据规模的缩放定律
最后,研究还深入探讨了
预训练数据规模
△
实验发现了一个明显的规律:随着预训练数据量的增加,模型在零样本手部动作预测中的误差稳步下降,在真实机器人操作中的成功率持续上升。这种清晰的缩放行为(Scaling Beha vior)表明,通过进一步扩大人类视频数据的规模,有望持续提升VLA模型的性能。
这项成果标志着,利用
非结构化人类视频
论文链接:https://arxiv.org/abs/2510.21571