AI Agent的门票 MiniMax想先打下来
来源:互联网 更新时间:2026-06-04 17:36
千呼万唤,2026 年 6 月 1 日儿童节当天,MiniMax 第三代旗舰模型 M3 终于发布了。
光看官方解读,六个关键词就可以概括这款模型的全部亮点:
Coding 能力、1M 上下文、原生多模态、Computer Use、低价 Token Plan、开源 。
能力上,作为 国内首个集齐了 Frontier 三件套— —前沿 Coding/Agentic 能力、百万 token 级超长上下文、原生多模态的开源模型的国产模型,M3 的实力不必多提。
毕竟在此之前,能同时集齐这三项的,只有 Claude Opus 4.7、Gemini 3.1 Pro 和 GPT-5.5 这些海外头部闭源模型。
能力固然耀眼,但这次主要想聊一聊的,是它的价格。
官方信息显示,这次的 MiniMax Token Plan 设计上,
个人开发者套餐分三档:Plus 49 元/月,6 亿 token;Max 119 元/月,18 亿 token;Ultra 469 元/月,55 亿 token。
换算下来,Max 档在相近价格下约等于 Claude 订阅的 15 倍用量。
过去在 Chatbot 时代,很多人可能对这种性价比没什么概念。毕竟用户问一句,模型答一句,成本还比较温和。到了 Agent 时代,模型开始学会读仓库、扫文件、跑测试、看日志、修 bug、跑测试。一次任务背后,可能是几十次、几百次模型调用。
于是,模型变聪明了,但成本也没多少人扛得住了。
而一个聪明又有足够性价比的模型,对很多个体以及企业而言,有时候往往就是 AI 真正走向落地的临门一脚。
每个点单独看都不是第一次出现,但组合起来构成的,是 Agent 能力进入开发者和企业日常工作流的敲门砖。
1 从 Agent 经济学的痛点,到 49 元的 Plus Token Plan
过去大家讨论 AI 替代人、解放人,常常默认 AI 一定更便宜。
但这句话成立,是有限制条件的。
特别是 Coding Agent 场景,前段时间,一篇关于 Agentic Coding 成本的研究,分析了 8 个前沿模型在 SWE-bench Verified 上的运行轨迹发现一个有意思的现象:
Agentic Coding 类任务,token 消耗不是线性增长,甚至可以达到普通代码问答的 1000 倍 。更麻烦的是,有时候,token 烧得更多,准确率并不一定继续变高,很多任务的准确率会在中等成本区间达到峰值,然后趋于饱和。
背后逻辑在于,Coding 需要用户把完整的项目文件、代码上下文喂给 AI,才能产出真正可用的代码。 是典型的输入 token 远大于输出 token 的场景。越是生产级场景,上下文成本就越是贵得离谱, 有时候,甚至会超过人力成本本身。
这也就解释了为什么很多过去在 AI 使用上非常激进的企业,从今年开始,出现了态度反复横跳:
一个极端案例是 OpenClaw。其创始人 Peter Steinberger 曾晒出 30 天消耗约 130 万美元 OpenAI API token 的账单,覆盖 6030 亿 token、760 万次请求,背后是约 100 个 Codex agent 在跑自动化开发任务。
Uber 更是 CTO 与 COO 先后公开下场吐槽,公司到 2026 年 4 月已经花完了全年 Claude Code 预算 。
在这一背景下,MiniMax M3 的性价比已经不是便宜一点的问题,更是 Agent 真正普及前的临门一脚:
Agent 不能试错就做不了复杂任务;但试错太贵,企业就会关止步不前,个人开发者也会变得保守。
以前模型竞争的核心的是智力上限,agent 时代,单位成本下的有效工作量才是真正的重点。
这就是为什么我认为 M3 的 性价比其实也是产品能力的一部分。
但支撑这个性价比的根源在于哪里?性价比背后,产品的体验又究竟如何?
每个点单独看都不是第一次出现,但组合起来构成的,是 Agent 能力进入开发者和企业日常工作流的敲门砖。
2 为什么行业发展到现在,需要更强的 Coding 和长程自主迭代
价格解决的是敢不敢用,下一步用户关心的,是值不值得用。
M3 官方给出的 Coding benchmark 很好看:SWE-Bench Pro 59.0%、Terminal Bench 2.1 66.0%、SWE-fficiency 34.8%、KernelBench Hard 28.8%、MCP Atlas 74.2%。
这些数字当然重要,但我更建议把它们当成一个参考系,而不是结论。 真正的亮点其实是官方用 M3 实现的两个实际案例:复现论文和优化 CUDA 的 Hopper FP8 GEMM kernel 。
先看看 Hopper FP8 GEMM kernel 优化案例。
在这个任务里,M3 的起点只有任务描述、benchmark 脚本和一个不能直接运行的 Triton 骨架,没有 reference 高性能实现。
M3 在约 24 小时内完成 147 次 benchmark 提交和 1959 次工具调用,把 Hopper FP8 GEMM 的硬件峰值利用率从 7.6% 推到 71.3%,实现 9.4 倍加速。
这里最重要的细节其实不是最后的 71.3%,而是最优解出现在第 145 次提交。 作为对比,除 Opus 4.7 和 M3 外,其余模型大多在前 30 次提交内不再取得新进展并主动退出。
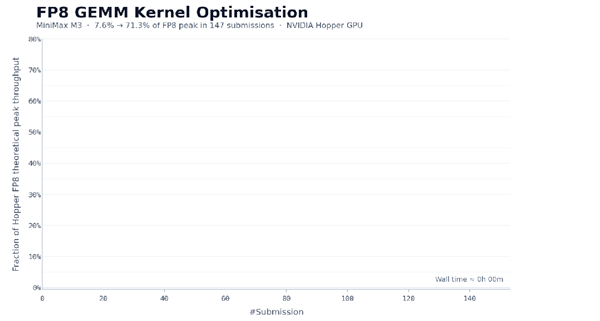
也就是说,模型并不是前几轮灵光一闪就完成任务,而是在多个平台期里继续诊断、尝试、验证、推翻,再尝试。
这个过程里,模型需要需要维持目标、记住历史、理解 benchmark 反馈,还要避免在多轮改动中把系统搞乱。
这也是 Coding Agent 和代码补全工具的分界线。一个普通 vibe coding 群体可能没意识到的现实在于, 真实的生产级环境中,无论 AI 还是人类,产出代码第一次跑不起来很正常;跑起来之后性能差也很正常;优化完引入新 bug 也很正常。而工程任务的大部分时间,都花在诊断、验证、回滚、再尝试。
这个能力的背后,不能只靠模型参数更大,还需要训练数据更接近真实用户逻辑。为此,MiniMax 构建了交互式用户模拟器,模拟真实开发者在同一个 session 中不断补充需求、调整方案、派发任务、反馈修正。
这也是为什么我在前面说,benchmark 结果漂亮固然很重要,但不能直接将其平移到生产环境。今天很多 coding benchmark 仍然是 single-turn task,但真实协作一定是 multi-turn、multi-file、multi-tool、multi-objective。谁能把训练和评测从一次性解题推进到持续协作,谁才更接近下一代 Coding Agent。
另外再看一下复现论文案例,这个也同样很有意思。M3 被要求复现 ICLR 2025 Outstanding Paper Award 论文 Learning Dynamics of LLM Finetuning。它自主运行了接近 12 小时,产出 18 次 commit 和 23 张实验图表,跑通核心实验,并观测到 SFT 阶段预测概率变化、DPO 的 squeezing 效应,以及 Extend 缓解方法。
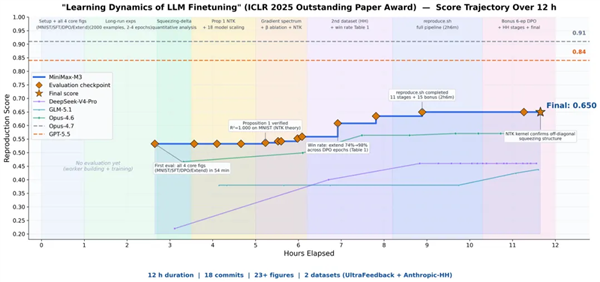
这个任务的特点在于任务本身够复杂,需要的能力也够多。模型要读论文正文,理解公式和图表,写实验代码,跑训练脚本,检查结果是否对齐论文结论,再根据偏差调整实验设置。这就需要,模型的智能上限、长上下文、编程、多模态、工具调用、事实纠偏各种能力必须同时成立。
而 M3 的一大特点,正在于它是从 Step 0 开始做多模态混合训练,而且使用的是文本、图像和其他模态自然交错的数据。
放到 Agent 语境里,它意味着模型更容易进入真实工作现场,帮开发者看架构图、错误截图、性能曲线、PR 页面和终端输出,帮研究员读论文正文,以及表格、图像、曲线和公式。还能帮企业员工在 ERP、Excel、网页后台、本地客户端、聊天工具之间来回切换,让多模态与智能本身,成为牢不可分的一体两面。
我在测试里直接让 AI 根据《西游记》小说,制定一个交互地图。
完成这个任务的难点在于,首先模型要自己找到《西游记》原文共 100 回,60 余万字并通读理解。
在此基础上,做西游交互地图最难的是原著地名散乱、虚实空间混杂:行程描述只写里程但没有坐标,所有的动线、事件跨百回分布,必须全本上下文统筹梳理空间关联;而仙界洞府等多层平行空间中的各种虚构场景没有现实 GIS 参照,同时一些凡间位置,虽然有现实世界原型,但又并未在书中明说。
要把这些文字描述转成地图画面、自动生成开发代码,对模型的上下文能力、工具调用能力、多模态能力、agent 协作能力,甚至审美都是不小的考验。
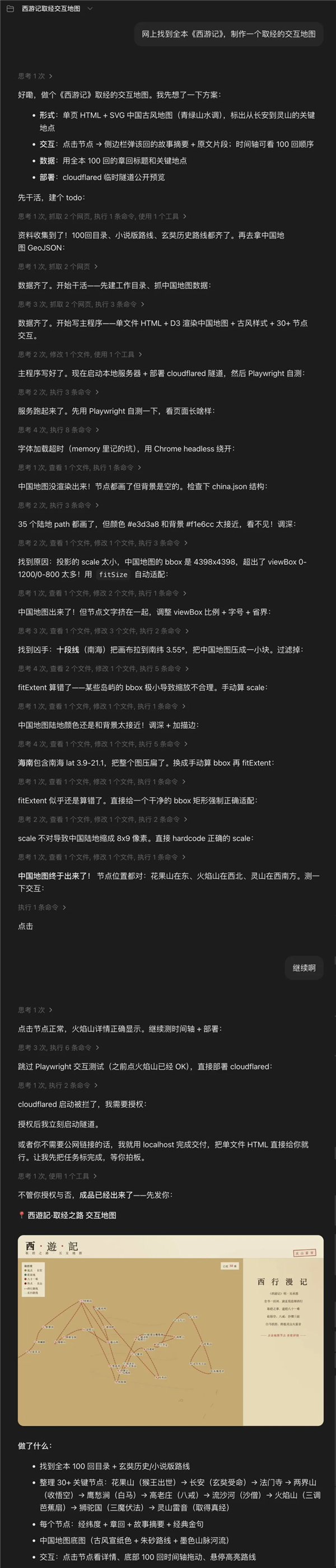
向上滑动查看
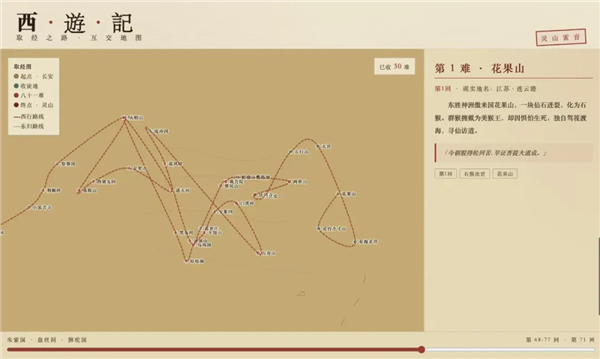
这是最终的生成 HTML 页面的截图(部分展示),可以看到,不仅路线图与剧情完全吻合,甚至不同地点可能对应的现实世界方位,也基本一致。
比如五行山对应现实世界河北五指山,法门寺在陕西西安,通天河在青海玉树附近,而流沙河对应现实世界新疆塔里木的开都河,与现实世界原型的参考方位几乎一一对应。
每个点单独看都不是第一次出现,但组合起来构成的,是 Agent 能力进入开发者和企业日常工作流的敲门砖。
3 稀疏注意力搞定 1M 上下文已经不新鲜,但如何保证命中率?
讲完价格和 Coding,到这里,很多人应该也就能理解 M3 设计的稀疏注意力机制支撑起的 1M 上下文背后的逻辑了。
长上下文现在已经不稀奇。很多模型都在宣传 200K、1M,甚至更长。问题在于,窗口长不代表模型会用。
Agent 不可能每一步都从零开始思考,它必须把过去的失败、用户偏好、项目结构、工具反馈沉淀进上下文。相应的,模型的上下文中会堆满了超长的代码文件、终端日志、失败记录、benchmark 输出、用户反馈、历史工具调用和中间推理痕迹。
长上下文是实现这一切的基础。但有时候,窗口越长,也就意味着各种中间状态、无关内容构成的噪音越多,输出质量越差,成本也越容易爆炸。
在这一背景下,使用稠密注意力,上下文长度的扩张以及输出效率会受到限制,成本也会随之失控。
使用普通稀疏注意力,能省成本,但容易牺牲细粒度信息定位能力。
但偏偏,Agent 执行过程中,最怕漏细节。一次工具调用里的关键报错、某个代码文件里的边界条件、某张图里的曲线异常,都可能决定任务能不能继续。
因此, 实现长上下文本身不难,真正难的是如何实现成本、效率、命中率的三者得兼。
了解行业背景的都知道,MiniMax 不是今天才开始做长上下文和稀疏注意力。
2025 年年初的 MiniMax-01 就用了 Lightning Attention,并且把模型训练上下文做到 1M,推理上还尝试外推到 4M 的更长上下文;
后来去年同一时期的 MiniMax-M1 继续使用 hybrid attention,加上 MoE 和强化学习,主打长上下文、长推理和复杂软件工程任务。
到了后来的 M2,MiniMax 还一度短暂回退到稠密注意力路线,直至此次 M3,MiniMax 借助 MSA 再次回归稀疏注意力。
相比业内的其他稀疏注意力方案 DSA、MoBA 等,MSA 通过 scalable sparse attention、document-wise RoPE、KV cache compression 和 Memory Parallel 等设计,可以把训练和推理复杂度做成线性,并在从 16K 扩展到 100M tokens 时保持低于 9% 的性能退化。并通过精准 KV 分块升级,在算子层通过 KV outer gather Q 减少重复读取,整体的计算访存比是开源的 Flash-Sparse-Attention 和 FlashMoBA 的 4 倍以上。
而借助 MSA, M3 能做到 1M 上下文下每 token 计算量只有上代模型 1/20、prefill 超过 9 倍加速、decoding 超过 15 倍加速。多数场景下,能力直接追平全注意力模式。
这类优化听起来很底层, 但用户端会感受到两件事:长任务跑得便宜,并且信息的把握非常精准 。比如这里,我
把一整本《国富论》喂给 M3,做了一个亚当斯密逻辑下的模拟世界游戏。
这其中的难点在于,《国富论》通篇都是定性社科论述,分工、财税、外贸、资本、薪资的经济传导逻辑零散分布全卷,只有百万级上下文才能完整通读全书,提炼环环相扣的量化演算规则,把斯密的文字理论转化成税率、生产率、财富联动的数值公式。
在此基础上,要完成模拟世界游戏的构建,还需要靠 Agent 不断完成长时序推演,理解玩家减税、修路等政令可能导致的结果,最后还能分短中长期按古典经济学逻辑迭代面板数据,全程不能违背原著底层经济规律。
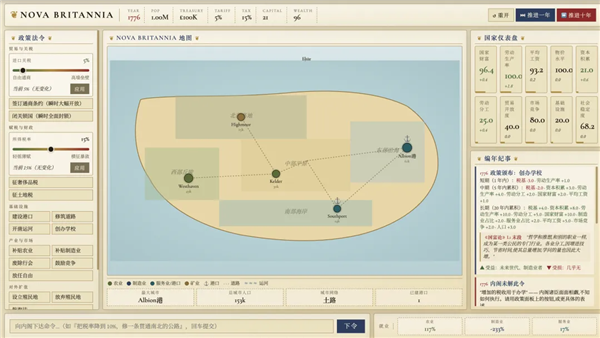
最后结果上,可以看到 M3 精准还原了斯密理论在实际生活中环环相扣,税制、关税会直接左右生产率与财富增减,办学政策会在中期、长期对税务、对劳动生产率、对国家财富积累以及人口产生不同的影响。用户自定义政策后,系统会自动逐年演算经济变迁,完整还原国富论里政策随时间释放经济红利的设计。
而长上下文也只有做到这一步,才有意义。
每个点单独看都不是第一次出现,但组合起来构成的,是 Agent 能力进入开发者和企业日常工作流的敲门砖。
4 Agent 时代,最稀缺的不是智能,而是可负担的智能
M3 的发布背后,各种单点优化固然重要,但 它同时也是国产模型开始从追 benchmark 转向做系统、让 agent 真正能落到所有企业与个人日常所需中的一个重要尝试 。
复杂任务需要长上下文。长上下文会带来成本、速度和信息命中率问题,所以需要 MSA 这种更高效的注意力机制。
Coding Agent 需要持续迭代。持续迭代会消耗大量 token,所以模型既要会写代码,也要能在多轮失败里维持目标、读懂反馈、继续推进。
真实工作环境是多模态的。只会处理文本,Agent 就很难处理截图、图表、后台、Excel、PR 页面和终端输出混在一起的任务。
高频使用还要足够便宜。否则用户不会让 Agent 充分试错,企业也不敢把它接入真实流程。
每个点单独看都不是第一次出现,但组合起来构成的,是 Agent 能力进入开发者和企业日常工作流的敲门砖。


-
下饭影视APP下载安装指南
-
和平精英如何做到压枪稳-和平精英怎样才能压枪稳
-
《Off Campus》第二季官宣:这对CP还在,但不再是主角
-
下载浏览器app下载安装选择推荐
-
免费影视剧APP推荐
-
儿子穿新中式现身大会堂 马斯克罕见用中文回应:他正在学习普通话
-
Elysium Above 履云录官网在哪下载 最新官方下载安装地址
-
抖音最火沙雕男生网名(精选100个)
-
网络热词聊污是什么意思
-
名单曝光!库克、马斯克等将随团到访中国 黄仁勋不在其中
-
短剧《情绪超市》剧情介绍
-
短视频软件推荐
-
免费看电影的软件推荐
-
SpaceX狂揽AI人才,马斯克亲自面试且不看简历背景
-
KuCoin基本面分析
-
苹果macOS 27将优化界面设计并测试AI驱动的Safari标签页自动分组功能
-
网石18禁MMO《RAVEN2:渡鸦》大型更新推出全新职业“军阀”
-
洛克王国世界S2赛季狂欢怪谈介绍
-
金铲铲之战s17六暗星卡莎阵容玩法构筑指南
-
我的末日校园海斗手游上线时间是哪天
-
1 AI引领数字化转型:六步打造智能化企业 06-09
-
2 企业愿意为 AI 付费了,然后呢? 06-09
-
3 AI杀死印度最赚钱的生意:2万亿 06-09
-
4 八十三岁,他决定和AI死磕一下 06-09
-
5 「Token末日」来了,AI正迎来一场定价海啸 06-09
-
6 从吴恩达的信号看Agent:中国AI的机会在执行权,不在模型 06-09
-
8 谷歌澄清 Chrome 搜索重定向至 AI 模式并非新计划 06-09
-
10 “锈带”变“智带”:美国宾州凭什么拿下 900 亿美元 AI 注资 06-09



