一周3.3k star,微软开启Skills自我进化,像训练神经网络一样训练技能
来源:互联网 更新时间:2026-06-01 09:14
从大模型的提示词到智能体的 Skills,表面上看是进化了,但仔细琢磨一下,又感觉没完全进化。
现在做智能体应用,越来越多的人把时间花在写 CLAUDE.md、Codex 的 skill 文件,以及各种 Agent 的 system prompt 上。这事儿听起来挺高级,但实际操作起来,本质就是手工试错:写一版,跑几个任务看看效果,觉得不对再改,改完再跑。这个循环,和当年手调 prompt 有什么区别?无非是对象从几句话变成了一整份文档。
细想一下,这其实有点荒诞。我们原本的目标是让更智能的 AI 替我们干活,结果到头来,反而是我们在花大力气教 AI 该怎么干活。
不过,这个问题也许终于看到了终点。微软本周开源了一个叫 SkillOpt 的框架,思路很有意思——把 Agent 的技能文档当作“可训练参数”,在文本空间里做优化,让技能文档自己学会进化。

核心逻辑并不复杂:不去训练模型权重,而是专门训练那份用来指导 Agent 行为的自然语言文档。在涵盖 7 个目标模型、6 个基准测试、3 种执行环境(直接对话、Codex、Claude Code)的全部 52 个评测组合中,SkillOpt 训练出的技能文档均达到最优或并列最优。
Skills 也能优化训练
一句话概括 SkillOpt 的核心洞察:Agent 的技能文档,本质上就是它的“外部权重”。既然模型内部的权重可以用梯度下降来优化,那外部权重凭什么就不能有一套系统化的训练方法?
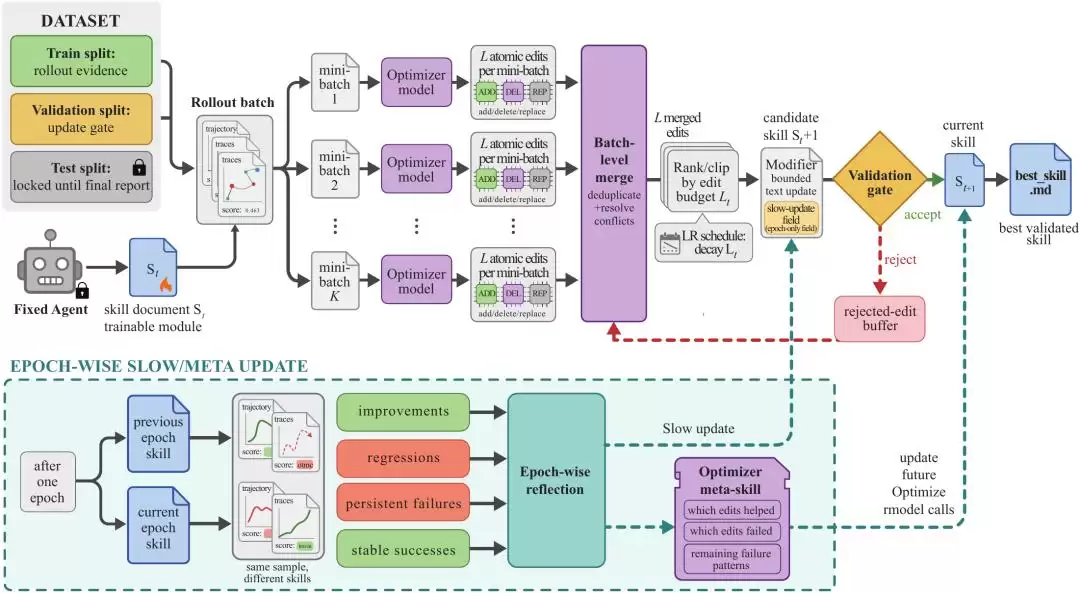
流程大致如下:冻结的目标模型使用当前技能执行任务,优化器模型则提出有边界的修改,最后通过保留的验证来决定候选是否成为新的当前技能。
训练循环:前向传播、反向传播、参数更新
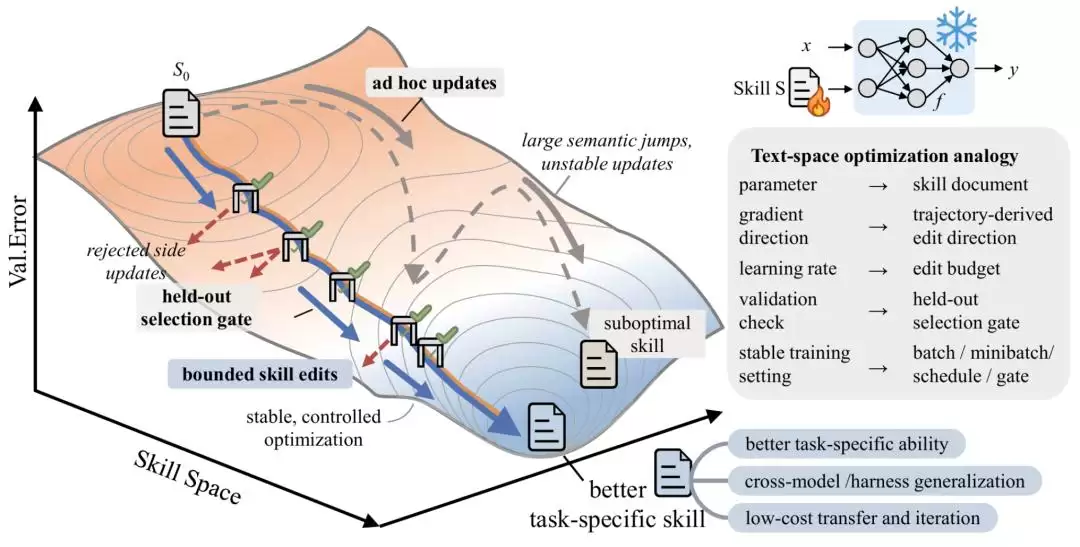
传统深度学习的训练循环,大家都熟悉:前向传播算 loss,反向传播算梯度,再用梯度更新权重。SkillOpt 把这个逻辑搬到了文本空间,一一对应:
Rollout(前向传播)
Reflect(反向传播)
Edit(参数更新)
Gate(验证门控)
整个循环会跑多个 epoch,每个 epoch 内又有多个 step,节奏上和训练神经网络几乎完全一致。
文本学习率:防止灾难性遗忘
训练神经网络时,学习率设太大容易导致灾难性遗忘——学了新东西,旧的就忘了。SkillOpt 在文本空间遇到了完全一样的问题:一次编辑改动如果太大,很可能把之前学到的有效规则覆盖掉。
解决方案很直接,引入一个“文本学习率”(textual learning rate):每一步允许的编辑操作数量设个上限。论文中默认是 lr=4,也就是每步最多进行 4 个 add/delete/replace 操作。这个约束迫使优化器每次只做小幅调整,从而保持训练的稳定性。
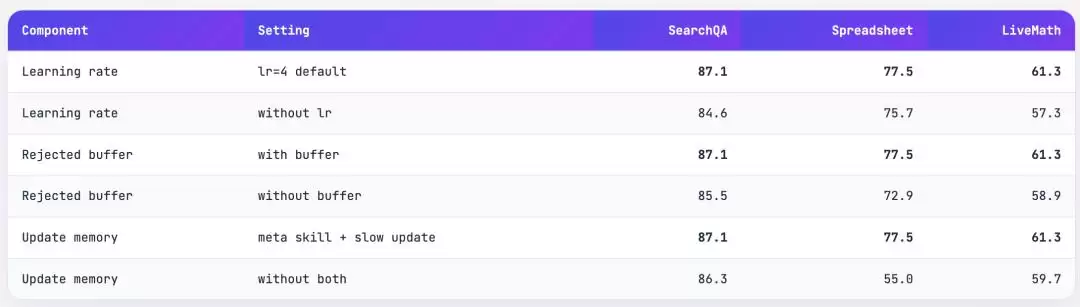
消融实验也验证了这个设计的必要性:去掉学习率约束后,SearchQA 上的性能从 87.1% 滑到 84.6%,SpreadsheetBench 从 77.5% 降到 75.7%,LiveMath 从 61.3% 降到 57.3%,降幅都相当明显。
被拒绝编辑的缓冲区:负反馈记忆
另一个精巧的设计是 rejected-edit buffer。当一个编辑提案被验证门控拒绝时,它不会被简单丢掉,而是进入一个缓冲区。优化器在后续的反思阶段能看到这些“失败的尝试”,从而避免重复提出类似的无效编辑。
这相当于给优化器提供了负梯度信息:不仅知道该往哪个方向走,还知道哪些方向已经试过、走不通。消融实验证实了它的价值:去掉 rejected buffer 后,SpreadsheetBench 的性能从 77.5% 骤降到 72.9%。
慢更新与元技能:长期记忆机制
SkillOpt 还引入了两个跨 epoch 的记忆机制:
Slow Update
Meta Skill
关键在于,这两个机制只在训练时存在。部署的时候,目标模型只需要那份最终的 best_skill.md,既不需要优化器模型,也不需要记忆模块,推理时的额外开销为零。
52 项评测全面领先
主实验:7 个模型 × 6 个基准 × 3 种环境
SkillOpt 的评测覆盖面很广:
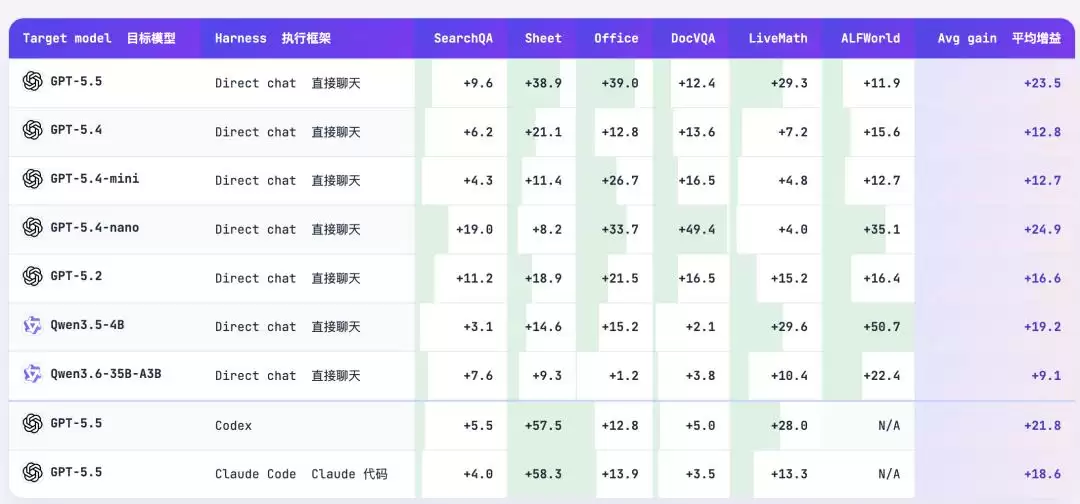
目标模型从 GPT-5.5、GPT-5.4、GPT-5.4-mini、GPT-5.4-nano、GPT-5.2,到 Qwen3.5-4B、Qwen3.6-35B-A3B,既有最强的闭源模型,也有 4B 参数的小模型。基准测试覆盖 6 种不同类型的任务:SearchQA(问答)、SpreadsheetBench(代码生成/电子表格操作)、OfficeQA(工具增强问答)、DocVQA(文档视觉问答)、LiveMathematicianBench(数学推理)、ALFWorld(具身智能体)。执行环境则包括直接对话、OpenAI Codex 和 Anthropic Claude Code 三种主流框架。
在全部 52 个(模型 × 基准 × 环境)评测组合中,SkillOpt 全部达到最优或并列最优。
几个值得注意的数据:
- GPT-5.5 直接对话模式:平均提升 +23.5 分,其中 SpreadsheetBench 提升 38.9 分,OfficeQA 提升 39.0 分
- GPT-5.4-nano(最小模型):平均提升 +24.9 分,DocVQA 提升 49.4 分,ALFWorld 提升 35.1 分
- GPT-5.5 + Codex 环境:SpreadsheetBench 提升 57.5 分
- GPT-5.5 + Claude Code 环境:SpreadsheetBench 提升 58.3 分
有趣的是,小模型的提升幅度反而更大。这说明技能文档对能力较弱的模型帮助更显著。一份好的操作手册,对新手的价值远大于对专家——这个直觉放在 AI Agent 身上同样成立。
对比实验:碾压所有基线方法
SkillOpt 对比了 6 种基线方法:无技能(no skill)、人工编写技能(human skill)、LLM 一次性生成技能(LLM skill)、Trace2Skill、TextGrad、GEPA。
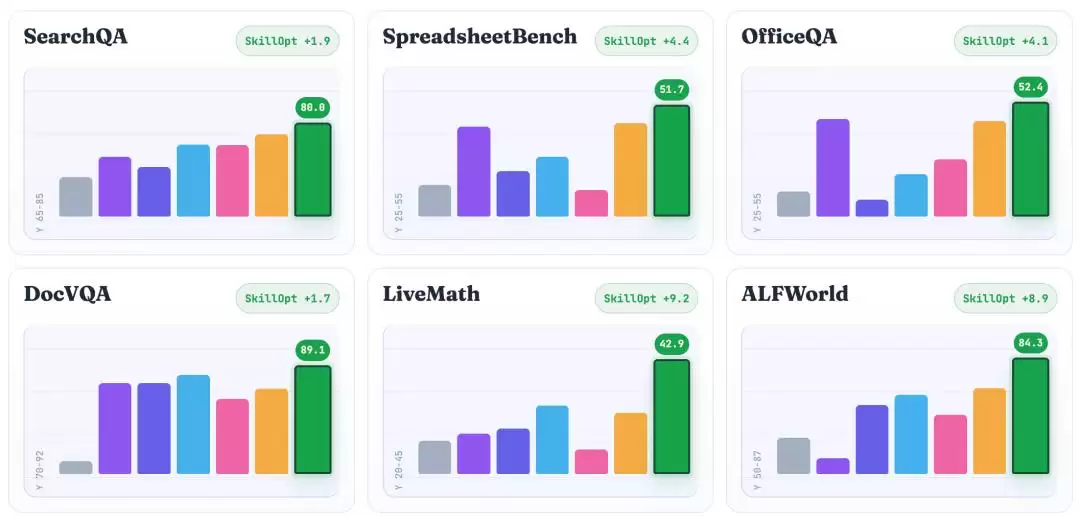
在每一个 benchmark 上,SkillOpt 都超过了最强的基线方法:
- SearchQA:超过最强基线 +1.9 分
- SpreadsheetBench:超过最强基线 +4.4 分
- OfficeQA:超过最强基线 +4.1 分
- DocVQA:超过最强基线 +1.7 分
- LiveMath:超过最强基线 +9.2 分
- ALFWorld:超过最强基线 +8.9 分
值得注意的是,TextGrad 和 GEPA 都是已有的文本优化方法。SkillOpt 对它们的优势说明,系统化的训练循环设计——学习率、验证门控、负反馈缓冲——确实比松散的自我修正更有效。
迁移实验:一次训练,多处部署
SkillOpt 训练出的技能文档表现出很强的迁移能力:
- :在 GPT-5.4 上训练的 LiveMath 技能,直接迁移到 GPT-5.4-nano 上使用,提升 15.2 分。不需要针对小模型重新训练。
跨模型迁移
- :在 Codex 环境中训练的 SpreadsheetBench 技能,直接迁移到 Claude Code 环境中使用,提升 31.8 分。这意味着,你在一个 Agent 框架里优化好的技能文档,换到另一个框架里依然有效。
跨环境迁移
- :即使用 GPT-5.4-nano 同时作为目标模型和优化器模型(自己优化自己),SpreadsheetBench 上仍然提升了 10.4 分。这说明 SkillOpt 的训练循环本身提供了足够的结构化约束,即使优化器不比目标模型更强,也能发现有效的改进方向。
自优化
- :最终部署时只需要一个 best_skill.md 文件。优化器模型、记忆模块、额外的推理开销,统统不需要。
部署极简
技能进化的可视化:从失败中学习
论文中展示了一个 ALFWorld 任务上的完整训练过程,目标模型是 GPT-5.4-mini,优化器是 GPT-5.5。
初始技能文档是一份简洁的 ALFWorld 操作指南。经过 4 个训练 step 后,技能文档中新增了这些规则:
- “将任何通用的目标容器实例视为有效”
- “维护一个严格编号的已搜索集合,不重复检查已观察过的位置”
- “在某一类位置连续多次未命中后,扩大搜索范围”
这些规则,都是从失败的轨迹中自动提炼出来的。比如第三条,就源自 Agent 在某些任务中反复搜索同一类位置却找不到目标物品的失败经验。优化器观察到这个模式后,提出了“扩大搜索范围”的规则。
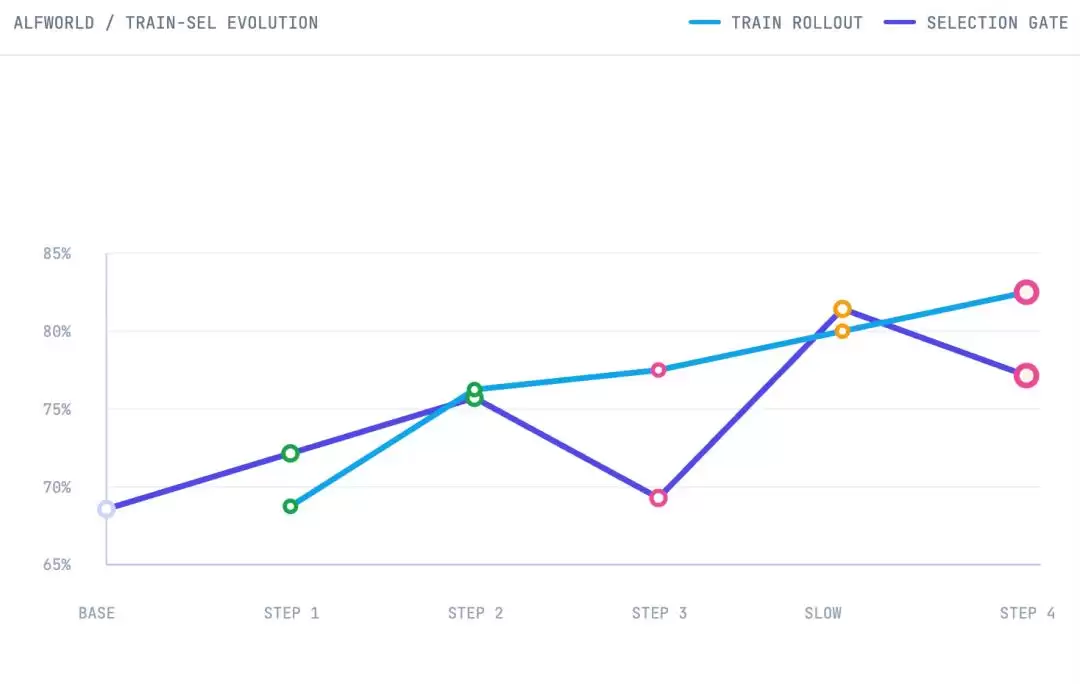
最终效果:ALFWorld 测试集的 hard 难度从 70.9% 提升到了 85.8%。
整个过程中,Step 3 的编辑一度导致验证集性能下降,但被 slow update 机制救回。Step 4 的训练集得分更高,但验证集没有提升,因此被门控拒绝。这种“提出假设、验证、接受或拒绝”的循环,和人类做科研的方法论如出一辙。
SkillOpt 告诉我们,智能体的一切,都是可以自我学习的。人类在 AI 工作流中的角色,可能又要往后退一步了。未来,我们会把更多的认知负担转移给机器。
-
下饭影视APP下载安装指南
-
灵宝派对手游下载安装地址推荐
-
和平精英如何做到压枪稳-和平精英怎样才能压枪稳
-
下载浏览器app下载安装选择推荐
-
《Off Campus》第二季官宣:这对CP还在,但不再是主角
-
4D采矿者官网在哪下载 最新官方下载安装地址
-
免费影视剧APP推荐
-
儿子穿新中式现身大会堂 马斯克罕见用中文回应:他正在学习普通话
-
Elysium Above 履云录官网在哪下载 最新官方下载安装地址
-
抖音最火沙雕男生网名(精选100个)
-
名单曝光!库克、马斯克等将随团到访中国 黄仁勋不在其中
-
短剧《情绪超市》剧情介绍
-
短视频软件推荐
-
免费看电影的软件推荐
-
KuCoin基本面分析
-
苹果macOS 27将优化界面设计并测试AI驱动的Safari标签页自动分组功能
-
网络热词聊污是什么意思
-
网石18禁MMO《RAVEN2:渡鸦》大型更新推出全新职业“军阀”
-
洛克王国世界S2赛季狂欢怪谈介绍
-
SpaceX狂揽AI人才,马斯克亲自面试且不看简历背景
-
1 开源个 Skill|彻底解决小红、小绿书配图难题 05-28
-
2 高德“问店选址”Skill接入钉钉悟空,AI赋能商家开店决策 05-28
-
7 2026 年 5 个最佳 Agent Skills 平台推荐 05-31
-
8 微软开启Skills自我进化!像训练神经网络一样训练技能 05-31
-
10 微信读书接入 AI Skill,一句话帮你理清阅读人生 06-02



